分布式限流介绍
限流的目的是通过对并发访问/请求进行限速或者在一个时间窗口内的请求进行限速来保护系统,一旦请求到达限制速率则可以拒绝服务、排队或等待、降级。
主要是通过压测时找出每个系统的处理峰值,然后通过处理设定峰值阈值来防止系统过载时,通过拒绝处理过载的请求来保障系统可用性。
分布式限流的几种维度
- 时间: 限流基于某段时间范围或者某个时间点,也就是我们常说的“时间窗口”,比如对每分钟、每秒钟的时间窗口做限定
- 资源: 基于可用资源的限制,比如设定最大访问次数,或最高可用连接数
上面两个维度结合起来看,限流就是在某个时间窗口对资源访问做限制,比如设定每秒最多100个访问请求。但在真正的场景里,我们不止设置一种限流规则,而是会设置多个限流规则共同作用,主要的几种限流规则如下:

一般开发高并发系统常见的限流有:
- 限制总并发数:如数据库连接池、线程池
- 限制瞬时并发数:如Nginx的 limit_conn 模块
- 限制时间窗口内的平均速率:如Guava的RateLimiter、Nginx的 limit_req 模块
- 限制远程接口调用速率
- 限制MQ的消费速率
- 等等…
- 还可以根据网络连接数、网络流量、CPU或内存负载
限流算法
令牌桶算法

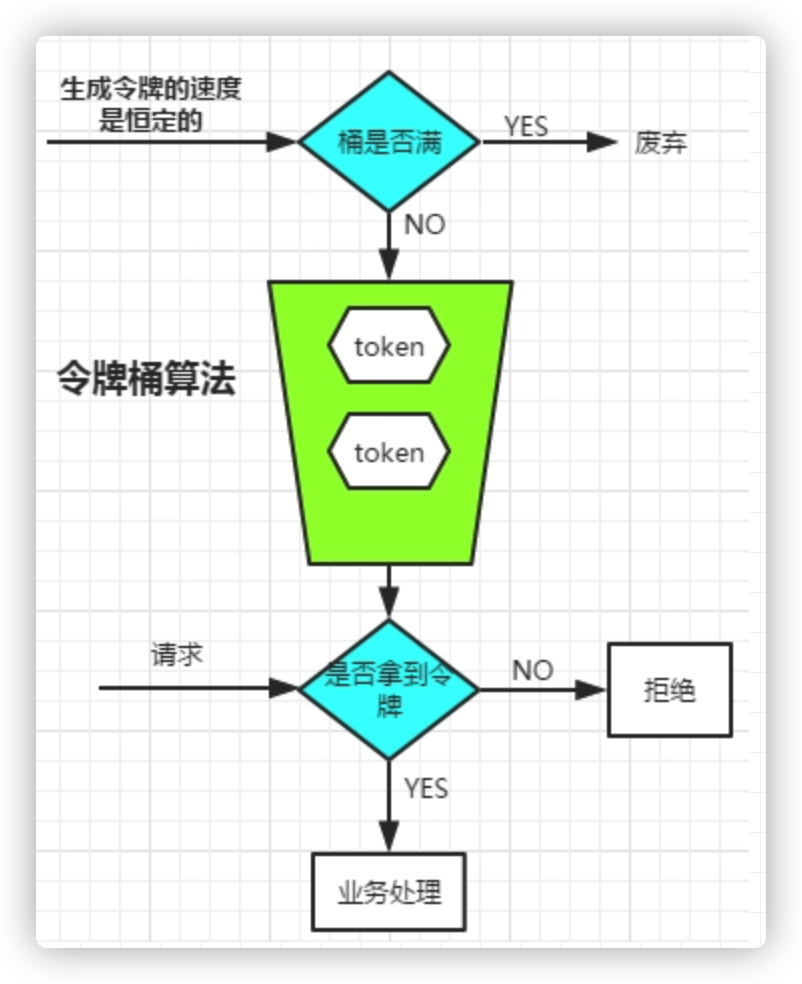

有两个关键的角色:
- 令牌:获取到令牌的Request才会被处理,其他Requests要么排队要么被直接丢弃
- 桶:用来装令牌的地方,所有Request都从这个桶里面获取令牌
两个关键流程:
生成令牌
这个流程涉及到令牌生成器和令牌桶,令牌桶是一个装令牌的地方,既然是个桶那么必然有一个容量,也就是说令牌桶所能容纳的令牌数量是一个固定的数值。
对于令牌生成器来说,它会根据一个预定的速率向桶中添加令牌,比如我们可以配置让它以每秒100个请求的速率发放令牌,或者每分钟50个。注意这里的发放速度是匀速,也就是说这50个令牌并非是在每个时间窗口刚开始的时候一次性发放,而是会在这个时间窗口内匀速发放。
在令牌发放器就是一个水龙头,假如在下面接水的桶子满了,那么自然这个水(令牌)就流到了外面。在令牌发放过程中也一样,令牌桶的容量是有限的,如果当前已经放满了额定容量的令牌,那么新来的令牌就会被丢弃掉。
获取令牌
每个访问请求到来后,必须获取到一个令牌才能执行后面的逻辑。假如令牌的数量少,而访问请求较多的情况下,一部分请求自然无法获取到令牌,那么这个时候我们可以设置一个“缓冲队列”来暂存这些多余的令牌。
缓冲队列其实是一个可选的选项,并不是所有应用了令牌桶算法的程序都会实现队列。当有缓存队列存在的情况下,那些暂时没有获取到令牌的请求将被放到这个队列中排队,直到新的令牌产生后,再从队列头部拿出一个请求来匹配令牌。
当队列已满的情况下,这部分访问请求将被丢弃。在实际应用中我们还可以给这个队列加一系列的特效,比如设置队列中请求的存活时间,或者将队列改造为PriorityQueue,根据某种优先级排序,而不是先进先出。算法是死的,人是活的,先进的生产力来自于不断的创造,在技术领域尤其如此。
漏桶算法

漏桶算法的前半段和令牌桶类似,但是操作的对象不同,令牌桶是将令牌放入桶里,而漏桶是将访问请求的数据包放到桶里。同样的是,如果桶满了,那么后面新来的数据包将被丢弃。
漏桶算法的后半程是有鲜明特色的,它永远只会以一个恒定的速率将数据包从桶内流出。打个比方,如果我设置了漏桶可以存放100个数据包,然后流出速度是1s一个,那么不管数据包以什么速率流入桶里,也不管桶里有多少数据包,漏桶能保证这些数据包永远以1s一个的恒定速度被处理。
令漏洞算法 VS 漏洞算法
漏桶
漏桶的出水速度是恒定的,那么意味着如果瞬时大流量的话,将有大部分请求被丢弃掉(也就是所谓的溢出)。
令牌桶
生成令牌的速度是恒定的,而请求去拿令牌是没有速度限制的。这意味,面对瞬时大流量,该算法可以在短时间内请求拿到大量令牌,而且拿令牌的过程并不是消耗很大的事情。
最后,不论是对于令牌桶拿不到令牌被拒绝,还是漏桶的水满了溢出,都是为了保证大部分流量的正常使用,而牺牲掉了少部分流量,这是合理的,如果因为极少部分流量需要保证的话,那么就可能导致系统达到极限而挂掉,得不偿失。
滑动窗口

上图中黑色的大框就是时间窗口,我们设定窗口时间为5秒,它会随着时间推移向后滑动。我们将窗口内的时间划分为五个小格子,每个格子代表1秒钟,同时这个格子还包含一个计数器,用来计算在当前时间内访问的请求数量。那么这个时间窗口内的总访问量就是所有格子计数器累加后的数值。
比如说,我们在每一秒内有5个用户访问,第5秒内有10个用户访问,那么在0到5秒这个时间窗口内访问量就是15。如果我们的接口设置了时间窗口内访问上限是20,那么当时间到第六秒的时候,这个时间窗口内的计数总和就变成了10,因为1秒的格子已经退出了时间窗口,因此在第六秒内可以接收的访问量就是20-10=10个。
滑动窗口其实也是一种计算器算法,它有一个显著特点,当时间窗口的跨度越长时,限流效果就越平滑。打个比方,如果当前时间窗口只有两秒,而访问请求全部集中在第一秒的时候,当时间向后滑动一秒后,当前窗口的计数量将发生较大的变化,拉长时间窗口可以降低这种情况的发生概率
限流组件
Guava RateLimiter 客户端限流
引入依赖项
1
2
3
4
| <dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</dependency>
|
非阻塞式的限流方案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| @Slf4j
@RestController
public class RateLimiterController {
private RateLimiter rateLimiter = RateLimiter.create(2.0);
@GetMapping("/tryAcquire")
public String tryAcquire(Integer count, @RequestParam(defaultValue = "0") Integer timeout) {
if (rateLimiter.tryAcquire(count, timeout, TimeUnit.SECONDS)) {
log.info("success, rate is {}", rateLimiter.getRate());
return "success";
} else {
log.info("fail, rate is {}", rateLimiter.getRate());
return "fail";
}
}
}
|
同步阻塞式的限流方案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| @Slf4j
@RestController
public class RateLimiterController {
private RateLimiter rateLimiter = RateLimiter.create(2.0);
@GetMapping("/acquire")
public String acquire(@RequestParam(defaultValue = "1") Integer count) {
rateLimiter.acquire(count);
log.info("success, rate is {}", rateLimiter.getRate());
return "success";
}
}
|
基于Nginx 的IP限流、服务器级别限流
nginx 的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
limit_req_zone $binary_remote_addr zone=iplimit:20m rate=10r/s;
limit_req_zone $server_name zone=serverlimit:10m rate=1r/s;
server {
listen 80
server_name www.rate-limiter.com
location /access-limit/ {
proxy_pass http://127.0.0.1:10000/;
limit_req zone=iplimit burst=2 nodelay;
limit_req zone=serverlimit burst=1 nodelay;
}
}
|
基于Nginx 的连接数限制和单机限制
nginx 的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
limit_conn_zone $binary_remote_addr zone=perip:20m;
limit_conn_zone $server_name zone=perserver:20m;
server {
listen 80;
server_name www.rate-limiter.com;
location /access-limit/ {
proxy_pass http://127.0.0.1:10000/;
limit_conn perip 1;
limit_conn perserver 100;
limit_req_status 504;
limit_conn_status 504;
}
}
|
TODO 基于Nginx + Lua + Redis 实现动态封禁 IP
基于Redis+Lua的分布式限流
Lua 限流脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
local key = KEYS[1]
redis.log(redis.LOG_DEBUG, 'key is ', key)
local limit = tonumber(ARGV[1])
local current = tonumber(redis.call("get", key) or "0")
if current + 1 > limit then
return false
else
redis.call("INCRBY", key, "1")
redis.call("expire", key, "2")
return true
end
|
使用 spring-boot-starter-data-redis 结合 lua 限流脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| @Slf4j
@Aspect
@Component
public class AccessLimiterAspect {
@Autowired
private RedisLuaAccessLimiter redisLuaAccessLimiter;
@Pointcut("@annotation(AccessLimiter)")
public void cut() {
}
@Before(value = "cut()")
public void before(JoinPoint joinPoint) {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
AccessLimiter annotation = method.getAnnotation(AccessLimiter.class);
String key = annotation.key();
if (StringUtils.isBlank(key)) {
Class<?>[] parameterTypes = method.getParameterTypes();
key = method.getName();
String paramTypes = Arrays.stream(parameterTypes)
.map(Class::getName)
.collect(Collectors.joining(","));
key += ("#" + paramTypes);
}
Integer limit = annotation.limit();
redisLuaAccessLimiter.limitAccess(key, limit);
}
}
|






