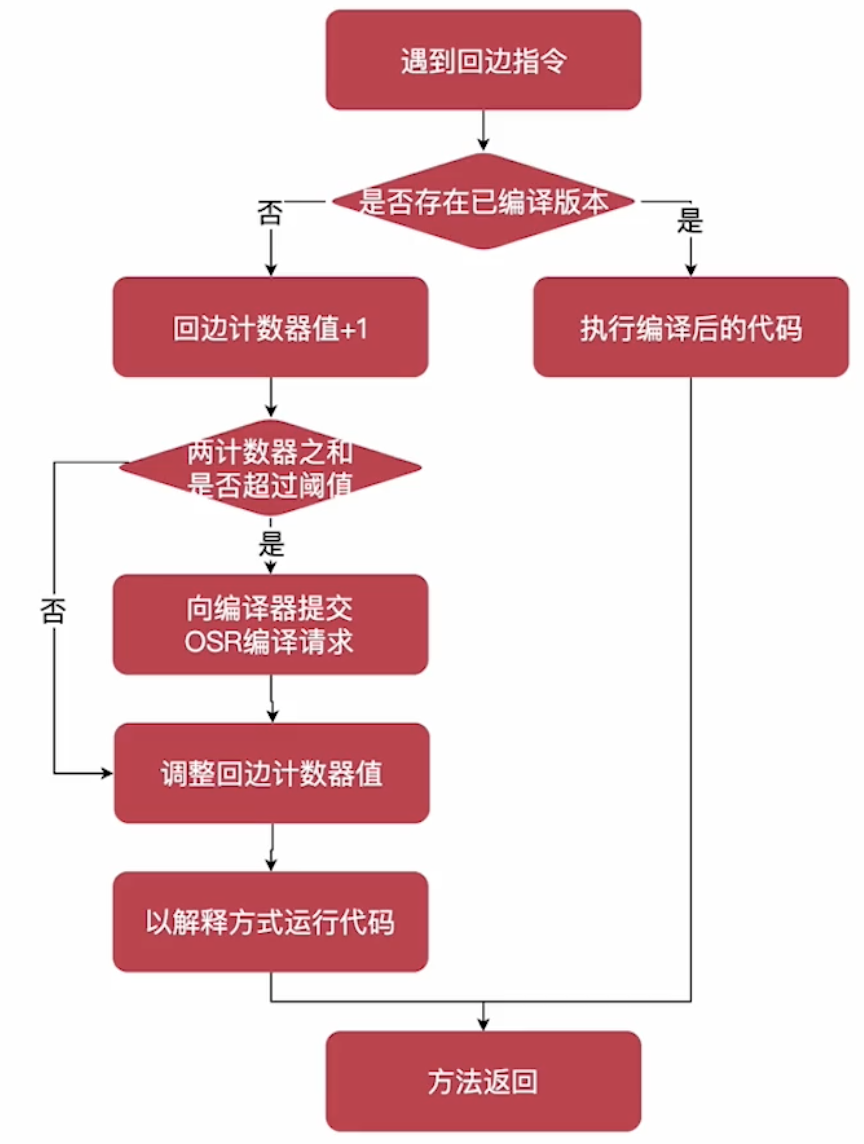
NIDD概述
NIDD: Non-IP Data Delivery
NIDD 的功能可用于处理非结构化的数据(也被称为非IP)的移动发起(MO)和移动(MT)通信 。这种对AF的输送是通过以下两种机制之一完成的:
通过NIDD的API传输
使用UPF基于点对点的N6通道传输
NIDD使用一个非结构化的PDU会话来处理NEF。UE可以在PDU会话建立过程中获得一个非结构化的PDU会话到NEF。NIDD API是否应该为一个PDU会话调用,取决于订阅中DNN/S-NSSAI组合的“NIDD的NEF标识”的存在。如果订阅包含与DNN和S-NSSAI信息对应的“NIDD的NEF标识”,则SMF选择该NEF并为该PDU会话使用NIDD API。
如果没有启用RDS (Reliable Data Service)服务,NEF将使用配置的策略将AF Identifier和UE Identity映射到DNN/S-NSSAI组合。如果启用了RDS, NEF将根据RDS端口号和可能用于将AF Identifier和User identity映射到DNN的策略来确定关联关系。
NEF还支持基于NIDD API向一组终端分发移动终止消息。如果在MT NIDD请求中包含外部组标识符,NEF使用UDM将外部组标识符解析为一个SUPIs列表,并将消息发送给组中的每个终端,并建立一个PDU会话。
协议配置选项(PCO)可用于传输NIDD参数进出终端(如最大包大小)。在UE和SMF之间的5GSM信令中,PCO被发送。NIDD参数通过N29接口发送给NEF,也通过NIDD接口发送给NEF。
通过NEF触发NIDD配置
如果NEF收到SMF的NIDD连接建立请求,如果终端没有NIDD配置,NEF可能会向AF发送NIDD配置触发,NEF根据本地配置确定目的URI。NEF应向确定的目标URL发送一个HTTP POST请求,该请求应包含一个NiddConfiguarationTrigger数据类型:
- NEF标识符,
- AF标识符,和
- gpsi作为终端标识。
AF应该用一个HTTP 200 OK响应来确认HTTP POST请求。然后,AF可以按照章节4.4.12.3中的描述启动NIDD配置过程。
通过AF和NIDD delivery触发NIDD配置
3GPP TS 29.122[4]第4.4.5小节描述了AF触发NIDD配置和NIDD交付的过程,但有以下差异:
- SCS/AS的描述适用于AF;
- 对SCEF的描述适用于NEF;
- MME/SGSN的描述适用于SMF;
- 对于连接的建立,NEF和SMF之间的交互应使用3GPP TS 29.541[24]中规定的Nnef_SMContext服务;
- 对于MO NIDD, SMF和NEF之间的交互应使用3GPP TS 29.541[24]中规定的Nnef_SMContext服务;和
- 对于MT NIDD, SMF和NEF之间的交互应使用3GPP TS 29.542[25]中规定的Nsmf_NIDD服务。
基于NIDD的NEF的相关程序
SMF-NEF 建立连接
当终端使用“非结构化”PDU Session类型建立PDU Session时,终端请求的DNN对应的订阅信息包含“NEF Identity for NIDD”(NEF ID),然后,SMF向DNN / S-NSSAI组合的“NEF ID”对应的NEF发起SMF-NEF连接建立过程。

步骤1-7和步骤9是非漫游场景下PDU会话建立过程;步骤1-9是漫游场景下的建立过程
如果DNN和S-NSSAI对应的订阅信息包含“NIDD的NEF标识”(NEF ID),则SMF应向NEF创建一个PDU会话。SMF向NEF调用Nnef_SMContext_Create Request (User Identity, PDU Session ID, SMF ID, NIDD信息,S-NSSAI, DNN, [RDS support indication], [Small Data Rate Control parameters], [Small Data Rate Control Status], [Serving PLMN Rate Control parameters])消息。如果在PDU会话建立请求消息中的PCO中包含支持可靠数据服务(RDS)的UE能力,则包括RDS支持指示。如果需要,SMF向NEF提供PDU会话的小数据速率控制参数。如果从AMF接收到SMF,则SMF向NEF提供小数据率控制状态(Small Data Rate Control Status)。如果服务PLMN打算对这个PDU会话实施服务PLMN速率控制(参见TS 23.501[2]的5.31.14.2条款),则SMF应向NEF提供服务PLMN速率控制参数,用于限制下行控制平面数据包的速率。
如果之前没有AF使用NEF对步骤2中收到的用户身份执行NIDD配置过程,那么NEF在步骤3之前启动NIDD配置过程(参见4.25.3)。
NEF创建一个NEF PDU session Context,并将其与User Identity和PDU session ID相关联。NEF调用Nnef_SMContext_Create Response (Cause, [RDS support indication], [Extended Buffering support indication], [NIDD parameters])向SMF确认UE的PDU会话建立。如果NEF支持并允许使用RDS,则它包括对SMF的RDS支持指示,而SMF将其包含在PCO中。如果NEF支持扩展缓冲,NEF在响应中包括扩展缓冲支持指示,并使用AMF订阅与移动相关的事件,以便在终端可达时接收指示。如果可用,NIDD参数(例如,最大数据包大小)将发送给SMF。
非漫游场景下,4.3.2.2.1条款第11-13步骤,home- routing漫游场景下,4.3.2.2.2条款第13-16步骤,UE请求PDU会话建立步骤。
非IP数据传输配置
通过NIDD API下发数据时,配置必要信息的流程如图4.25.3-1所示。
NIDD配置过程可以是NEF 发起或AF 触发: NEF发起从第1步开始,AF触发从第2步开始。

[可选]如果 NEF 对给定的 AF 要求 NIDD 配置,则 NEF 向 AF 发送 Nnef_NIDDConfiguration_TriggerNotify (GPSI, AF 标识, NEF ID)消息,请求对 GPSI 识别的 UE 进行 Nnef_NIDDConfiguration_Create 请求。
AF 向 NEF 发送一个 Nnef_NIDDConfiguration_Create 请求消息( GPSI 或外部组标识、AF标识、NIDD持续时间、T8目的地址、请求动作、TLTRI、可靠数据服务配置、MTC提供方信息)。
可靠数据业务配置是一个可选参数,用于配置可靠数据业务(如TS 23.501[2]第5.31.6条定义),包括发起方应用和接收方应用的端口号。如果请求动作被设置为“Update”或“Cancel”,则请求中包含TLTRI,否则请求中不包含TLTRI, NEF会将TLTRI分配给NIDD配置。如果存在可靠数据业务配置,可靠数据业务配置可能包括 MO 和 MT 的序列化格式,这些格式由AF为每个端口号支持。
- 注1:NIDD 持续时间是否可以设置为永不过期是由 AF 决定的。
- 注2:预计 AF 将被配置去使用的 NEF 与 SMF 在 UE 建立基于 NEF 的 NIDD 的 PDU 会话时所选择的 NEF 相同。
- 注3:当一个 PDU Session 有多个 AF 关联时,步骤 2 中提供的参数可以根据操作符策略或配置在 NEF 中配置。在这种情况下,步骤 2 中提供的任何与预置值冲突的参数都将被忽略。
- 注4:如果 AF 没有选择序列化格式,则假设 UE 应用程序知道 MT 通信将使用哪种序列化格式,或者 AF 将使用与 MO 通信相同的格式。
- 如果请求动作被设置为“取消”;它表明请求的目的是取消由TLTRI标识的事务,然后流继续进行第7步。如果被请求的动作设置为"Update",事务的目的是更新与配置相关的参数(即可靠数据服务)。否则,请求为新的NIDD配置,NEF存储收到的GPSI或外部组标识符、AF标识符、T8目的地址和NIDD持续时间。如果AF没有被授权执行此请求(例如,基于策略,如果SLA不允许),或者Nnef_NIDDConfiguration_Create请求格式不正确,NEF执行第7步,并提供一个Cause值适当地指示错误。根据配置的不同,NEF可能会更改NIDD持续时间。
- NEF 向 UDM 发送一个Nudm_NIDDAuthorisation_Get Request ( GPSI 或 External Group Identifier, S-NSSAI, DNN, AF Identifier, MTC Provider Information)消息,授权NIDD配置请求接收到外部组标识符或GPSI。
注5:NEF使用在步骤2中获得的AF标识符、外部组标识符或GPSI来确定将使用什么DNN来实现终端和AF之间的非结构化数据传输。这种确定是基于本地策略的。
注6:步骤2中的“MTC Provider Information”为可选参数。NEF应该验证所提供的MTC提供者信息,并可以根据配置将其覆盖到NEF选择的MTC提供者信息。NEF如何确定MTC提供者信息,如果在步骤2中没有出现,则留给实现(例如,基于请求的AF)。
UDM检查Nudm_NIDDAuthorisation_Get请求消息。
如果授权成功,并且步骤4中包含外部组标识符,则UDM将外部组标识符映射到内部组标识符和GPSIs列表,并将GPSIs映射到SUPIs。
- 注7:如果在第4步中包含了外部组标识符,那么当多个GPSI与同一个SUPI相关联时,UDM如何选择一个GPSI,则有待实现,例如,根据MTC提供商信息(如果收到了)或默认GPSI(如果没有收到)。
- UDM 向 NEF 发送一个Nudm_NIDDAuthorisation_Get 响应消息(单值或(SUPI和GPSI)、Result的列表),以确认接受了Nudm_NIDDAuthorisation_Get请求。如果UDM确定列表的大小超过了消息的容量,UDM将对列表进行分段,并将其以多个消息的形式发送(分段的详细信息见TS 29.503[52])。在此响应中,UDM返回SUPI(s)和GPSI(s)(如果可用的话)(当Nnef_NIDDConfiguration_Create Request包含GPSI时)。这允许NEF将该过程第2步中收到的AF请求与为每个UE或每个组成员UE建立的SMF-NEF连接关联起来。
- NEF向AF发送Nnef_NIDDConfiguration_Create 响应消息 (TLTRI、最大包大小、可靠数据服务指示和原因),以确认接受Nnef_NIDDConfiguration_Create请求。如果NIDD配置被接受,NEF分配一个TLTRI NIDD配置并将其发送给AF, NEF 在TLTRI、GPSI或外部组标识符,SUPI, PDU会话ID之间创建了一个关联关系, 是从SMF-NEF连接过程的步骤2中的 SMF 收到的(见图4.25.2-1: SMF-NEF Connection Procedure)。在MT NIDD过程中,NEF将使用TLTRI和GPSI或External Group Identifier来确定用于发送非结构化数据的PDU会话的SUPI(s)和PDU会话ID。在MO NIDD过程中,NEF将使用SUPI(s)和PDU会话ID(s)来获得TLTRI, GPSI。“可靠数据服务指示”表示NIDD配置中是否启用了“可靠数据服务”。“Maximum Packet Size”是NIDD报文的最大大小。
非IP数据传输支持NEF锚定上行(MO)数据传输

- UE根据控制平面CIoT 5GS优化中UPF锚定上行数据传输的步骤1-4发送带有非结构化数据的NAS消息(见4.24.1条款)。如果启用了可靠数据服务,则包含可靠数据服务头。
- [可选] 家用路由漫游时,V-SMF向H-SMF发送Nsmf_PDUSession_TransferMOData请求,包括上行(MO)小数据。
- (H-)SMF向NEF发送Nnef_SMContext_Delivery Request (User Identity, PDU会话ID,非结构化数据)消息。
- 当NEF接收非结构化数据,并找到一个NEF PDU会话上下文和相关T8目的地址,那么它将非结构化数据发送到AF所确定的T8目的地址在Nnef_NIDD_DeliveryNotify请求(GPSI,非结构化数据,可靠的数据服务配置)。如果终端的PDN连接没有关联T8目的地址,则丢弃数据,不发送Nnef_NIDD_DeliveryNotify请求,从步骤6继续流。当启用可靠数据服务时,可靠数据服务配置用于为AF提供额外的信息,如表明确认是否被请求,以及发起者应用程序和接收者应用程序的端口号。
- AF以Nnef_NIDD_DeliveryNotify Response (Cause)响应NEF。
- NEF向SMF发送Nnef_SMContext_Delivery Response。如果NEF无法交付数据,例如由于AF配置缺失,NEF会向SMF发送适当的错误码。
- [可选]家用路由漫游时,H-SMF响应V-SMF的Nsmf_PDUSession_TransferMOData (Result Indication)响应。
NEF 锚定下行(MT)数据传输

1a. 如果AF已经激活了某个终端的NIDD服务,并且有下行非结构化数据要发送给终端,AF会向NEF发送一个Nnef_NIDD_Delivery Request (GPSI, TLTRI,非结构化数据,可靠数据服务配置)消息。可靠数据服务配置是一个可选参数,用于配置可靠数据服务,它可以用来指示是否请求可靠数据服务的确认以及发起方应用程序和接收方应用程序的端口号。
1b. AMF向NEF表示该UE已可达。在此基础上,NEF重新开始向UE交付缓冲的非结构化数据。
NEF根据与NIDD配置和用户身份相关联的DNN确定5GS QoS流上下文。如果在第1步中发现了与GPSI相对应的NEF 5GS QoS Flow Context,则NEF检查AF是否被授权发送数据,以及是否没有超过其配额或速率。如果这些检查失败,则跳过步骤3-15,并在步骤17中返回适当的错误代码。
NEF使用Nsmf_NIDD_Delivery Request将非结构化数据转发给(H-)SMF。如果NEF在建立SMF-NEF连接期间在Nnef_SMContext_Create Response中表示支持扩展缓冲,那么NEF将保留一份数据的副本。NEF使用Nsmf_NIDD_Delivery Request将非结构化数据转发给(H-)SMF。如果NEF在建立SMF-NEF连接期间在Nnef_SMContext_Create Response中表示支持扩展缓冲,那么NEF将保留一份数据的副本。
漫游时,H-SMF向V-SMF发送Nsmf_PDUSession_TransferMTData,包括下行(MT)小数据。
(V-)SMF根据本地策略和在建立SMF-NEF连接时NEF是否在Nnef_SMContext_Create Response中表示支持扩展缓冲来决定是否应用扩展缓冲。(V-)SMF压缩报头,通过Namf_Communication_N1N2MessageTransfer服务操作将数据和PDU会话ID转发给AMF。如果扩展缓冲应用,那么(V-SMF)在Namf_Communication_N1N2Message Transfer中包含“扩展缓冲支持”的指示。
如果AMF确定SMF无法访问终端(例如,如果终端处于MICO模式或终端被配置为扩展空闲模式DRX),那么AMF拒绝来自SMF的请求。如果SMF没有订阅UE可达事件,AMF可以在拒绝消息中包括指示SMF不需要向AMF触发Namf_Communication_N1N2MessageTransfer请求。
如果SMF包含扩展缓冲支持指示,AMF在拒绝消息中表示SMF确定扩展缓冲时间的估计最大等待时间。当终端处于MICO模式时,AMF会根据下次预期的定时注册定时器更新过期时间或实际执行情况来确定“最大等待时间预估”。如果终端配置为扩展空闲模式DRX, AMF将根据下一个PagingTime Window的启动时间来确定“估计最大等待时间”。AMF会存储SMF已被告知UE不可达的指示。
漫游时,V-SMF向H-SMF发送Nsmf_PDUSession_TransferMTData (Result Indication)响应。如果V-SMF从AMF收到一个“估计的最大等待时间”,并且应用了扩展缓冲,V-SMF也会把这个“估计的最大等待时间”传递给H-SMF。
如果(H-)SMF收到故障提示,(H-)SMF也会向NEF发送故障提示。如果(H-)SMF收到了“估计的最大等待时间”并且应用了扩展缓冲,(H-)SMF在故障指示中包含扩展缓冲时间。扩展缓冲时间由(H-)SMF决定,应该大于或等于估计的最大等待时间。NEF为扩展缓冲时间存储DL数据。如果收到后续的下行数据包,NEF不会再发送任何Nsmf_NIDD_Delivery Request消息。这个过程在这个步骤停止。
如果AMF在步骤5中确定终端可达,则应用控制平面CIoT 5GS优化程序(第4.24.2条)中UPF锚定的移动终端数据传输步骤3至6。
如果可靠数据服务头指示确认被请求,则UE应对接收到的DL数据响应确认。
如果AMF在第9步中对终端进行了分页触发NAS过程,AMF应启动第4.2.4.2条中定义的UE配置更新过程,以分配一个新的5G-GUTI。
如果终端对寻呼没有响应,AMF会向(V-)SMF发送寻呼失败通知。否则,该过程在步骤13继续。
在漫游情况下,如果V-SMF收到AMF的故障通知,则V-SMF向H-SMF发送Nsmf_PDUSession_TransferMTData (Result Indication)响应。
如果(H-)SMF收到失败通知,则SMF指示NEF请求的Nsmf_NIDD_Delivery失败。如果应用扩展缓冲,则NEF将清除数据副本。这个过程在第17步继续。
在控制平面CIoT 5GS优化程序(第4.24.2条)中应用UPF锚定的移动终端数据传输的步骤9至11。
AMF通知(V-)SMF数据已被转发。
漫游时,V-SMF向H-SMF发送Nsmf_PDUSession_TransferMTData (Result Indication)响应,表示数据已被转发
(H-)SMF表示数据已转发给NEF。如果应用扩展缓冲,则NEF将清除数据副本。
NEF向AF发送一个Nnef_NIDD_Delivery Response (cause)。
可靠数据服务确认指示用于指示是否从终端收到了对MT NIDD的确认。在步骤1中如果可靠数据服务请求,然后Nnef_NIDD_Delivery响应发送到AF从问题或收到确认后,如果没有收到确认,那么Nnef_NIDD_Delivery响应发送到AF导致价值表明还没有收到任何确认。
NIDD 授权更新

UDM可以使用Nudm_NIDDAuthorisation_UpdateNotify Request (SUPI, GPSI, S-NSSAI, DNN, Result)消息向NEF发送NIDD授权更新信息来更新用户的NIDD授权。
NEF向UDM发送Nudm_NIDDAuthorisation_UpdateNotify Response (cause)消息以确认授权更新。
如果授权被删除,NEF应启动第4.25.8条规定的SMF-NEF连接释放程序。
NEF通过向AF发送Nnef_NIDDConfiguration_UpdateNotify Request (GPSI, TLTRI, Result)消息来通知AF用户的授权状态已经改变。
AF用Nnef_NIDDConfiguration_UpdateNotify Response消息响应NEF。
SMF 启动 SMF-NEF 连接释放

当PDU会话释放被启动,并且如果NEF被选择为控制平面CIoT的锚定,5GS优化启用了非结构化PDU会话类型,如第4.3.4.2条所述,然后SMF对该DNN / S-NSSAI组合对应的“NEF ID”对应的NEF启动一个SMF-NEF Connection Release过程。
SMF执行4.3.4.2章节中的“PDU会话释放步骤”中的步骤1。
如果NEF被选为锚定控制平面CIoT 5 g的优化使PDU会话的非结构化PDU会话类型如4.3.2.2条款所述,SMF发起SMF-NEF连接释放这个PDU会话发送Nnef_SMContext_Delete请求(用户标识、PDU会话ID、S-NSSAI款,释放原因(Release Cause)消息给NEF。
NEF删除与User Identity和PDU Session ID相关联的NEF PDU Session Context。NEF发送Nnef_SMContext_Delete Response (Cause, [Small Data Control Rate Status], [APN Rate Control Status])给终端确认释放SMF-NEF会话。如果PDU会话使用小数据速率控制,NEF包含“小数据速率控制状态”。
4.3.4.2章节中的“PDU Session释放步骤”中的步骤3-15。
NEF 启动 SMF-NEF 连接释放
在以下情况下,NEF会启动SMF-NEF连接释放过程:
—当UDM的NIDD授权更新请求表示该用户不再被授权使用NIDD时,或者
图4.25.8-1描述了NEF Initiated SMF-NEF Connection Release procedure(基于AF的请求)。

AF可以通过向NEF调用Nnef_NIDDConfiguration_Delete Request (TLTRI)来指示用户的NIDD SMF-NEF连接不再需要。
NEF删除与TLTRI相关的NEF PDU session Context,并通过调用Nnef_NIDDConfiguration_Delete Response对AF的响应来确认NIDD配置的删除。
NEF通过向SMF调用Nnef_SMContext_DeleteNotify Request来通知SM上下文信息的删除。
SMF通过对NEF调用Nnef_SMContext_DeleteNotify Response来确认该通知。
如果不再需要PDU会话,SMF将执行PDU会话释放步骤(参见4.3.4.2)中的步骤2-11。
基于NIDD Authorization Update的NEF Initiated SMF-NEF Connection Release流程如图4.25.8-2所示。

- 在UDM的NIDD授权更新中,NEF可能决定它需要释放相应的SMF-NEF连接。
- NEF会删除对应的NEF PDU session Context,并通过对SMF调用Nnef_SMContext_DeleteNotify Request来通知SM上下文信息的删除。
- SMF通过对NEF调用Nnef_SMContext_DeleteNotify Response来确认该通知。
- 如果不再需要PDU会话,SMF将执行PDU会话释放步骤(参见4.3.4.2)中的步骤2-11。
NEF 锚定组NIDD通过NEF锚定单播MT数据
图4.25.9-1描述了AF发送组NIDD到外部组标识符的过程。在第4.25.3条规定的NIDD配置过程中,NEF已经在UDM的帮助下解决了外部组标识符到单个supi的映射,这是一个先决条件。NEF在第4.25.5条中规定的独立MT NIDD程序被NEF重用,以单播MT数据到每个终端。

- 如果AF已经使用NIDD配置程序条款4.25.3激活NIDD服务的问题,非结构化数据发送到组被外部组标识符,AF发送一个Nnef_NIDD_Delivery请求(外部组标识符、TLTRI非结构化数据,可靠数据服务配置)消息发送给NEF。“可靠数据服务配置”为可选参数,用于配置“可靠数据服务”。当非结构化数据被发送到外部组标识符时,AF不应在可靠数据服务配置中请求确认。
- 根据现有的终端组NIDD配置(参见4.25.3),NEF向AF发送单个Nnef_NIDD_Delivery Response,以确认步骤1中的组NIDD delivery请求已被接受。
- NEF使用NEF锚定的移动终端数据传输程序(在第4.25.5条的步骤2-16中指定)向组中的每个终端发送相同的MT NIDD。
- 对组内所有终端执行步骤3后,NEF以Nnef_NIDD_GroupDeliveryNotify消息发送聚合响应。如果由于UE省电导致某些目标UE无法到达,那么NEF不会缓冲MT NIDD,但在这一步中,它可以在响应AF时包括这些UE的预期可达性的指示。如果向特定终端交付失败,NEF中可能会包含cause值。