[TOC]
1 编译器优化
1.1 字节码是如何运行的?
解释执行:由解释器一行一行翻译执行
- 优势在于没有编译的等待时间
- 性能相对差一些
编译执行:把字节码编译成机器码,直接执行机器码
- 运行效率会高很多,一般认为比解释执行快一个数量级
- 带来了额外的开销
那么如何查看自己的java是解释执行还是编译执行呢?
1 | $ java -version |
mixed mode 代表混合执行,部分解释执行、部分编译执行。
-Xint:设置JVM的执行模式为解释执行模式
1
2
3
4$ java -Xint -version
java version "1.8.0_251"
Java(TM) SE Runtime Environment (build 1.8.0_251-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.251-b08, interpreted mode)-Xcomp:JVM优先以编译模式运行,不能编译的,以解释模式运行
1
2
3
4$ java -Xcomp -version
java version "1.8.0_251"
Java(TM) SE Runtime Environment (build 1.8.0_251-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.251-b08, compiled mode)-Xmixed:以混合模式运行
一般情况下,我们的代码一开始一般由解释器解释执行。但是当虚拟机发现某个方法或代码块的运行特别频繁的时候,就会认为这些代码是热点代码(如何定位?)。为了提高热点代码的执行效率,会用即使编译器(也就是JIT)把这些热点代码编译城与本地平台相关的机器码,并进行各层次的优化(操作系统的不同、CPU架构的不同)
1.2 Hotspot 的即时编译器 C1
- 是一个简单快速的编译器
- 主要关注局部性的优化
- 适用于执行时间较短或启动性能有要求的程序。例如。GUI应用对界面启动速度就有一定要求。、
- 也被称为 Client Compiler
1.3 Htospot 的即时编译器 C2
- 是为长期运行的服务器端应用程序做性能调优的编译器
- 适用于执行时间较长或对峰值性能有要求的程序
- 也被称为是 Server Compiler
1.4 分层编译
从JDK7开始,正式引入了分层编译的概念,可以细分为 5 种编译级别:
- 解释执行
- 简单 C1 编译:会用 C1 编译器进行一些简单的优化,不开启 Profiling(JVM性能监控)
- 受限的 C1 编译:仅执行带方法调用次数以及循环回边执行次数Profiling的 C1 编译
- 完全C1编译:会执行带有所有Profiling的C1代码
- C2 编译:使用C2编译器进行优化,该级别会启用一些编译耗时较长的优化,一些情况下会根据性能监控信息进行一些非常激进的性能优化
级别越高,应用启动越慢,优化的开销越高,峰值性能也越高。
1.5 分层编译- JVM参数配置示例
- 只想开启 C2:-XX:-TieredCompilation(禁用中间编译层(123层))
- 只想开启 C1:-XX:+TieredCompilation -XX:TieredStopAtLevel=1
1.6 如何找到热点代码?思路?
基于采样的热点探测
周期性检查各个线程的栈顶,如果发现某一些方法总是出现在各个栈顶,那就说明是热点代码。
基于计数器的热点探测
大致思路是为每一个方法甚至是代码块建立计数器,然后统计执行的次数,如果超过一定的阈值,那就说明它是热点代码。Hotspot虚拟机采用的就是基于计数器的热点探测。
1.7 Hotspot 内置的两类计数器
方法调用计数器(Invocation Counter)
用于统计方法被调用的次数,在不开启分层编译的情况下,在 C1 编译器下的默认阈值是 1500 次,在 C2 模式下是 10000次。也可以哦那个 -XX:CompileThreshold=X 指定阈值
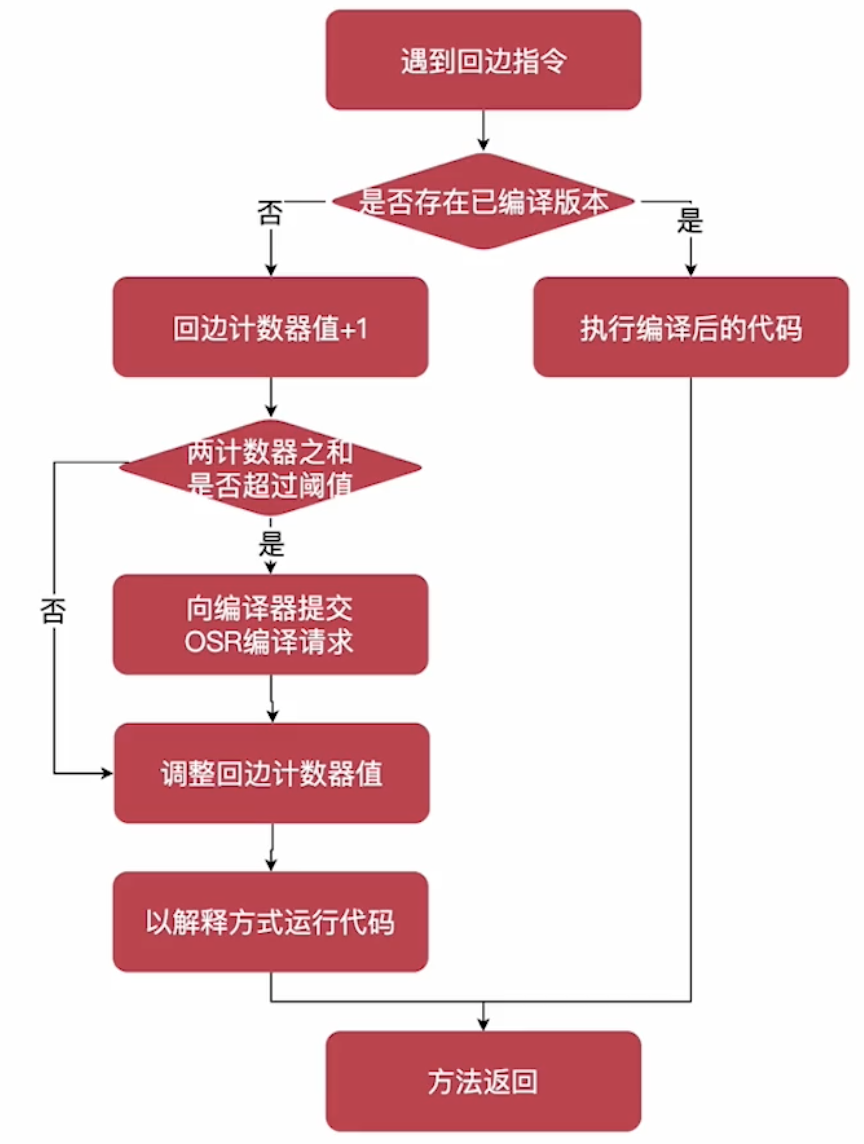
回边计数器(Back Edge Counter)
- 用于统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”(Back Edge)。在不开启分层编译的情况下,C1 编译器心爱的默认阈值 13995,C2 默认为 10700,可使用 -XX:OnStackReplacePercentage=X指定阈值
- 建立回边计数器的主要目的是为了触发 OSR (OnStackReplacement)编译,参考文档(https://www.zhihu.com/question/45910849/answer/100636125)
当开启分层编译时,JVM会根据当前编译的方法数以及编译线程数来动态调整阈值,-XX:CompileThreshold、-XX:OnStackReplacePercentage 都会失效。
1.8 方法调用计数器流程

如果不做任何设置,方法调用次数统计的并不是方法被调用的绝对次数,而是一个相对的执行频,即一段时间之内方法被调用的次数。当超过一定的时间限度,如果方法的调用次数荏苒不足以让它提交给及时编译器编译,那这个方法的调用计数器就会减少一半,这个过程称为方法调用计数器热度的衰减,而这段时间就称为此方法统计的半衰周期。进行热度衰减的动作是在虚拟机进行垃圾手机是顺便进行的,可以使用虚拟机参数-XX:-UseCounterDecay来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码。另外,可以使用-XX:CounterHalfLifeTime参数设置半衰周期的时间,单位是秒。
1.9 回边计数器流程
1.10 方法内联
1.10.1 什么是方法内联?示例?
1 | package com.example; |
所谓的方法内联就是把目标方法的代码复制到发起调用的方法之中,避免发生真实的方法调用,从而减少压栈和出栈的作用
1.10.2 发生方法内联的条件
方法体足够小
热点方法:如果方法体小于325字节会尝试内联,可用
-XX:FreqInlineSize修改方法体大小。非热点方法:如果方法体小于35字节,也会尝试内联,可用
-XX:MaxInlineSize修改大小。被调用方法运行时的实现可唯一确定
static方法、private方法及final方法,JIT可以唯一确定具体的实现代码。
public的实例方法,指向的实现可能是自身、父类、子类的代码,当且仅当JIT能够唯一确定方法的具体实现时,才有可能完成内联。
1.10.3 使用方法内联的注意点:
- 尽量让方法体小一点;
- 尽量使用 final、private、static关键字修饰方法,避免因为多态,需要对方法做额外检查;
- 在某些场景下,可通过JVM 参数修改阈值,从而让更多方法内联。
1.10.4 方法内联可能带来的问题
内联是用空间换时间的一种做法,也就是及时编译器在方法调用期间把方法调用连接在一起,但是经过内联的代码会变多,而增加的代码量取决于方法的调用次数以及方法本身的大小。
在一些极端情况下,内联可能会导致
- CodeCache(热点代码的缓存区,及时编译代码和本地方法代码)的溢出,导致JVM退化成解释执行模式;
1.10.5 内联相关JVM参数


1.10.6 方法内联测试代码
1 | public class InlineTest { |
内联启动JVM参数:-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining

不内联启动JVM参数:-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining -XX:+FreqInlineSize=1

但是,一般来说不建议使用这些JVM参数,默认的就好,现代JVM是相当智能的。
1.11 逃逸分析、标量替换、栈上分配
1.11.1 逃逸分析
逃逸分析:分析变量能否逃出它的作用域。
可以细分为 4 种场景:
- 全局变量赋值逃逸
- 方法返回值逃逸
- 实例引用逃逸
- 线程逃逸
- 赋值给类变量或可以在其他线程中访问的实例变量
代码示例:
1 | /** |
JVM 会针对以上4种场景进行分析,然后会为对象做一个逃逸状态标识,一个对象主要有 3 种逃逸状态标识:
- 全局级别逃逸:一个对象可能从方法或者当前线程中逃逸,主要有以下几种场景:
- 对象被作为方法的返回值;
- 对象作为静态字段(static field)或者成员变量(field);
- 如果重写了某个类的
finialze()方法,那么这个类的对象都会被标记为全局逃逸状态并且一定会放在堆内存中。
- 参数级别逃逸
- 对象被作为参数传递给一个方法,但是在这个方法之外无法访问/对其他线程不可见;
- 无逃逸状态:一个对象不会逃逸
1.11.2 标量替换
标量:不能被进一步分解的量
- 基础数据类型
- 对象引用
聚合量:可以进一步分解的量
- 字符串
那么什么是标量替换呢?逃逸分析确定该对象不会被外部访问,并且对象可以进一步被分解,JVM不会创建该对象,而是创建它的成员变量来代替。
代码展示:
1 | class Person { |
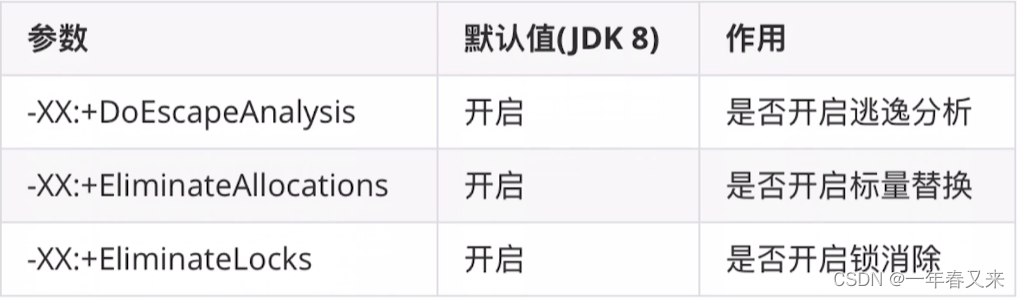
JVM 参数:-XX:+EliminateAllocaions 开启标量替换(JDK8 默认开启)
1.11.3 栈上分配
在 Java 中,绝大多数对象都是放在堆里面的,当对象无用时,由垃圾回收器回收。
栈上分配,顾名思义,就是通过逃逸分析,能够确认对象不会被外部访问,就在栈上分配对象,在栈上分配对象,就可以在栈帧出栈的时候销毁对象了,通过栈上分配就可以降低垃圾回收的压力。
1.11.4 相关JVM参数