1 OpenTSDB 概述
OpenTSDB是基于HBase的分布式、可伸缩的时间序列数据库。它存储的是时间序列数据,时间序列数据是指在不同时间点上收集到的数据,这类数据反映了一个对象随时间的变化状态或程度。
1.1 架构
OpenTSDB由时间序列守护进程(TSD)和一组命令行实用程序组成。与OpenTSDB的交互主要通过运行一个或多个TSD来实现。每个TSD都是独立的。没有主服务器,没有共享状态,因此您可以根据需要运行任意数量的TSD来处理您向其投入的任何负载。每个TSD使用CloudTable集群中的HBase来存储和检索时间序列数据。数据模式经过高度优化,可快速聚合相似的时间序列,从而最大限度地减少存储空间。TSD的用户不需要直接访问底层存储。您可以通过HTTP API与TSD进行通信。所有通信都发生在同一个端口上(TSD通过查看它收到的前几个字节来确定客户端的协议)。
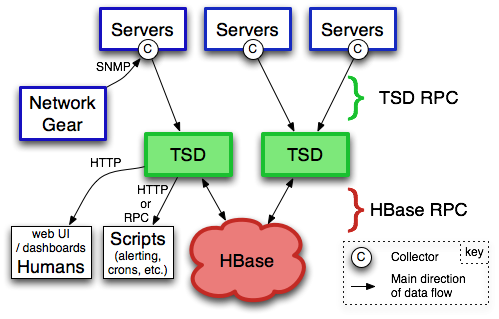
1.2 基本概念
data point:时间序列数据点,包括metric、timestamp、value和tag。表示某个metric在某个时间点的数值。
metric:指标项。例如,在系统监控中的CPU使用率、内存、IO等指标。
timestamp:UNIX时间戳(自Epoch以来的秒或毫秒),即value产生的时间。
value:某个metric的值,是JSON格式的事件或直方图/摘要。
tag:标签,是由Tagk和Tagv组成的键值对。用于描述该点所属的时间序列。
标签允许您从不同的源或相关实体中分离出类似的数据点,因此您可以轻松地单独或成组地绘制它们。标签的一个常见用法是使用生成数据点的机器名称以及机器所属的集群或池的名称来注释数据点。这使您可以轻松地制作显示每个服务器的服务状态的仪表盘,以及显示跨逻辑服务器池的聚合状态的仪表盘。
1.3 OpenTSDB系统表简介
OpenTSDB是基于HBase存储时序列数据的,在集群中开启OpenTSDB后,系统会在集群中创建4张HBase表。OpenTSDB系统表如下表所示。
请不要人为去修改这4张HBase表,因为这可能会导致OpenTSDB不可用。
| 表名 | 说明 |
|---|---|
| OPENTSDB.DATA | 用于存储数据点,OpenTSDB的所有数据都存储在这个表中。OpenTSDB按照salt进行分区,默认20个region,暂不支持设置。 |
| OPENTSDB.UID | 用于存储UID映射,数据点中的每个metric,tag都会映射成UID,同时每个UID反向映射为metric,tag,这些映射关系存储在这个表中。 |
| OPENTSDB.TREE | 用于存储metric的结构信息,默认未开启该特性。 |
| OPENTSDB.META | 用于存储时间序列索引和元数据,默认未开启该特性。 |
2 安装
2.1 运行时要求
要实际运行OpenTSDB,您需要满足以下条件:
- Linux系统
- Java运行时环境1.6或更高版本
- HBase 0.92 或更高版本
- GnuPlot 4.2 或更高版本
2.2 手动安装
当然,如果为了尽快上手,你也可以standalone模式(该模式独立运行zookeeper,hbase数据保存在本地)安装 HBase。(所以如果需要好的性能,整套大数据集群是少不了的)
opentsdb的安装方式有两种:源码编译安装和RPM包安装。
2.2.1 源码编译安装
1 | git clone git://github.com/OpenTSDB/opentsdb.git |
如果要卸载的话,执行 make uninstall。
2.2.2 RPM 包安装
1 | 直接从 github 上下载 OpenTSDB 的 release 版本的 RPM 包。 |
注: 安装时会提示下面两个问题
gnuplot-4.6.2-3.el7.x86_64: [Errno 256] No more mirrors to try.
gnuplot-common-4.6.2-3.el7.x86_64: [Errno 256] No more mirrors to try.
这个是应为CentOS中官方的yum源默认是国外的源,除非挂载VPN,否者不发找到镜像。
解决方法:
1 | 先下载阿里源 |
再重新安装OpenTSDB。
2.2.3 建表
配置完成后,我们通过下面命令在 HBase 中建立 opentsdb 所需的表。默认情况下 opentsdb 建立的 HBase 表启用了 lzo 压缩。需要开启 Hadoop 中的 lzo 压缩支持, 这里我们直接在下面脚本中把 COMPRESSION 的支持关闭。修改 /usr/share/opentsdb/tools/create_table.sh,设置 COMPRESSION=NONE,并且在文件开始处设置 HBase 所在目录。之后执行该脚本,在 HBase 中创建相应的表,命令如下:
1 | # COMPRESSION 的值有:NONE, LZO, GZIP or SNAPPY, |
2.2.4 启动
启动 OpenTSDB,service opentsdb start 或者 nohup tsdb tsd &。
通过浏览器访问 http://localhost:4242/查看是否安装成功。
2.3 Docker 安装
还有一种更快速便捷的方法,就是直接使用 docker 安装。
1 | docker run -d -p 4242:4242 --name opentsdb petergrace/opentsdb-docker |
-d表示在后台运行,
-p绑定主机端口,
–name为容器命名为opentsdb
下次可以直接使用:
docker start opentsdb启动
docker stop opentsdb停止
docker rm opentsdb删除
3 配置
OpenTSDB所有的配置都在 link. 这里列出来的配置基本都有默认值,但是有些需要根据环境和性能做出改变,具体如下表:
| 配置项 | 默认值 | 描述 | 修改值 |
|---|---|---|---|
| tsd.core.preload_uid_cache | false | 是否在TSD启动的时候,预热UID缓存数据,为了提升性能,需要开启 | true |
| tsd.core.auto_create_metrics | false | 一个新的metric存入tsdb时,是否自动为其生成UID,如果true,存入成功,反之,失败。(按照最大优化性能的目标来说,应该预先为所有的metric生成UID,但是实际中预先不知道所有的metric,所以这个值需要设置为true) | true |
| tsd.http.cachedir | 无 | tsd写临时文件的目录 根据实际环境设置,比如/tmp/opentsdb | |
| tsd.http.request.enable_chunked | false | Http写入数据时是否支持一次写入大批量的数据 | true |
| tsd.http.request.max_chunk | 4096 | 写入的批量数据的上限 根据需要增大,比如65535 | |
| tsd.http.staticroot | 无 | opentsdb页面的静态资源文件目录 安装目录下 ./build/staticroot | |
| tsd.network.port | 无 | tsd读写数据的端口 根据实际配置 比如9099 | |
| tsd.query.timeout | 0 | tsd查询的timeout,如果为0,则不会timeout 合理配置。 比如200 | |
| tsd.storage.enable_appends | false | 2.2版本,tsd 写数据到HBase有两种方式,一种是每来一条数据append到hbase, 一种是先缓存大量数据到tsd内存,然后进行compaction,一些性写入。推荐Append方式 | true |
| tsd.storage.enable_compaction | true | append打开,这种就关闭 | false |
| tsd.storage.fix_duplicates | false | 相同时间存储相同metric的时候(重复数据),最新写入的覆盖前面的值 | true |
| tsd.storage.hbase.zk_basedir | /hbase | hbase 的zk的目录 | 根据实际配置 |
| tsd.storage.hbase.zk_quorum | localhost | hbase 的zk地址 | 根据实际配置 |
4 OpenTSDB API简介
OpenTSDB提供了基于HTTP或HTTPS的应用程序接口。请求方式是通过向资源对应的路径发送标准的HTTP请求,请求包含GET、POST方法。它的接口与开源OpenTSDB保持一致,请参见http://opentsdb.net/docs/build/html/api_http/index.html。