[TOC]
1 Kafka 核心概念详解 1.1 Kafka(MQ) 的应用场景 1.1.1 Kafka(MQ)之异步化、服务解耦、削峰填谷
异步化
服务解耦、削峰填谷
1.1.2 Kafka 海量日志收集
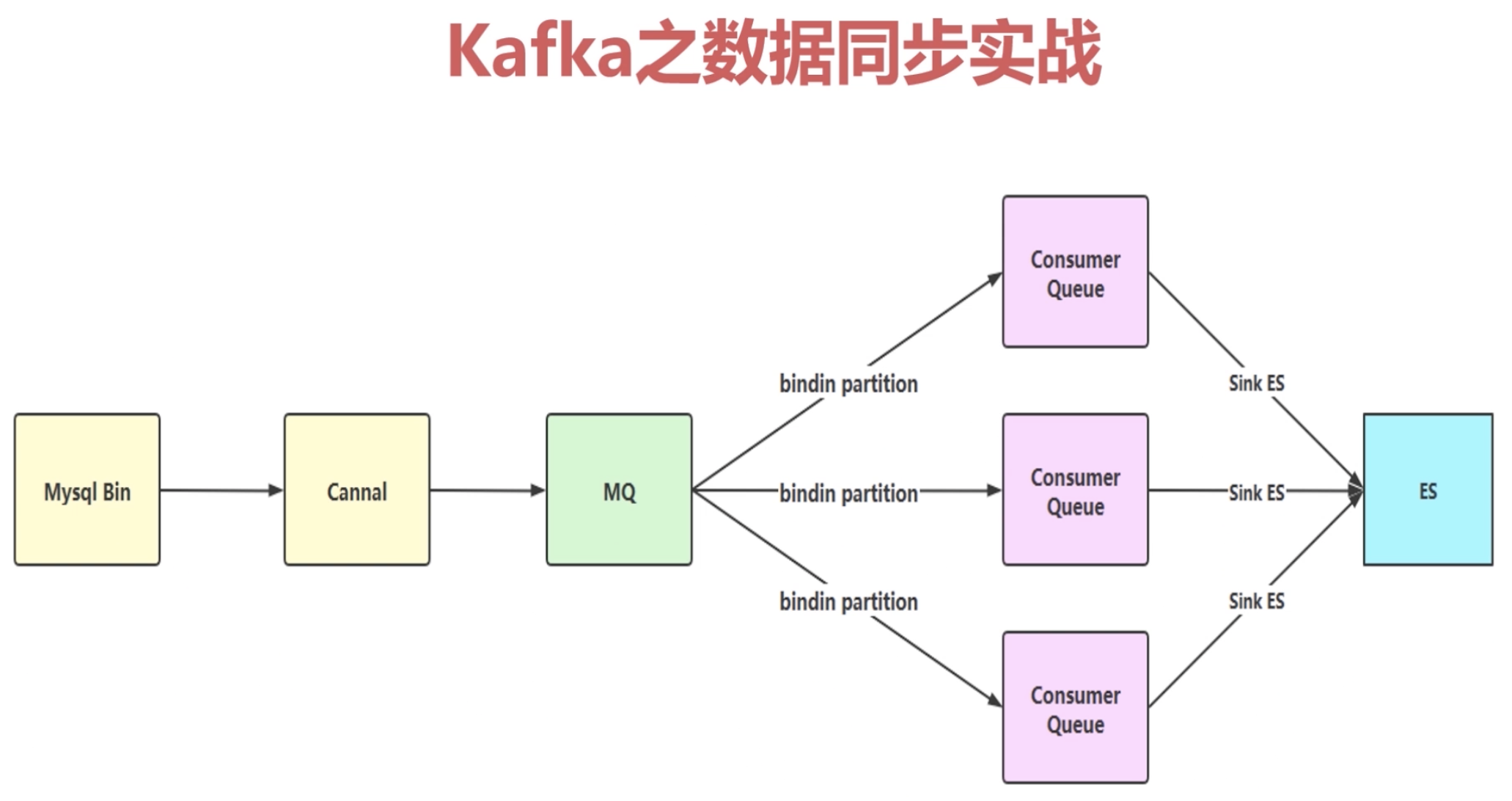
Kafka 之数据同步应用
Kafka 之实时计算
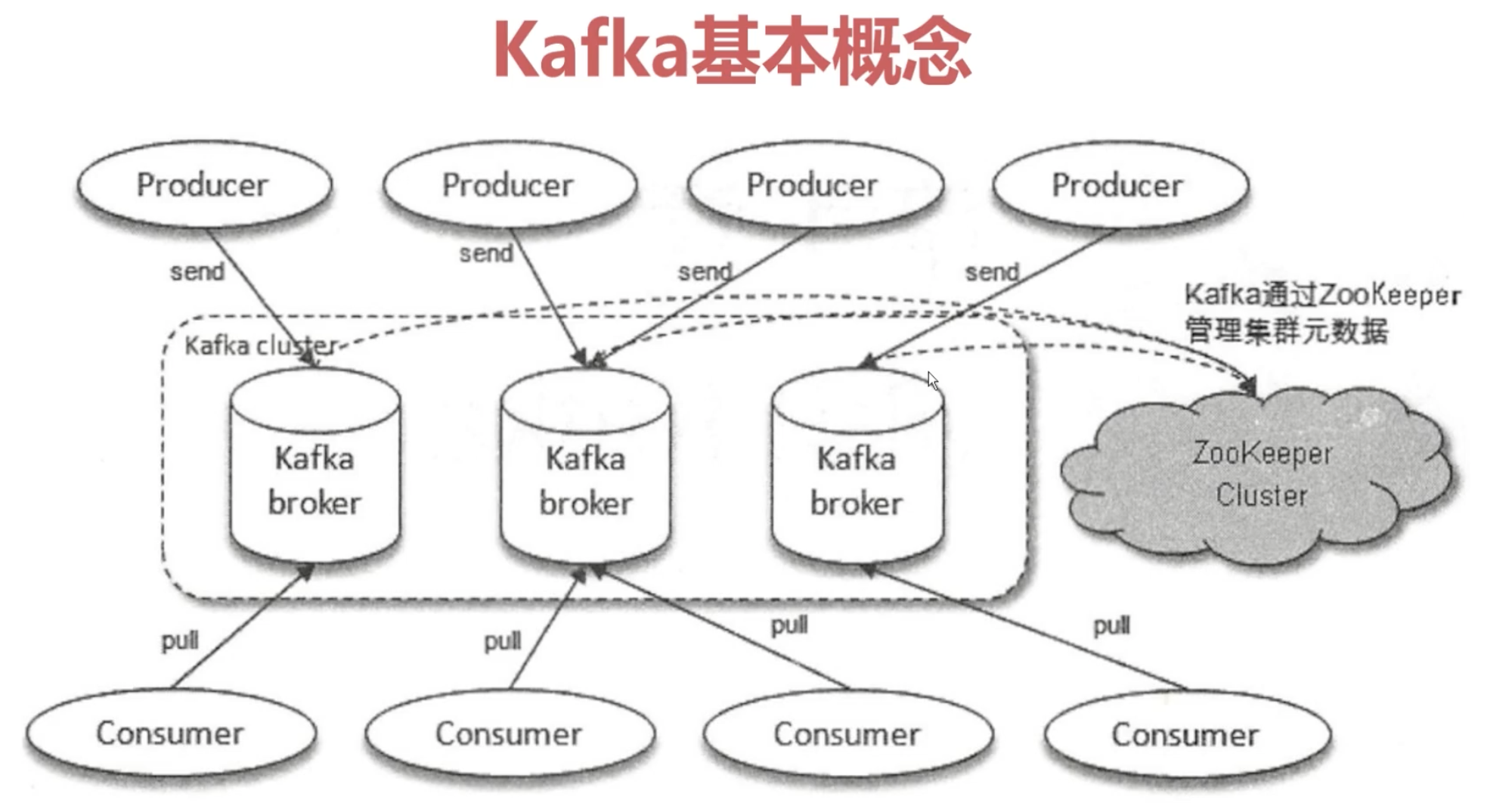
1.2 Kafka 基本概念 1.2.1 集群架构概念
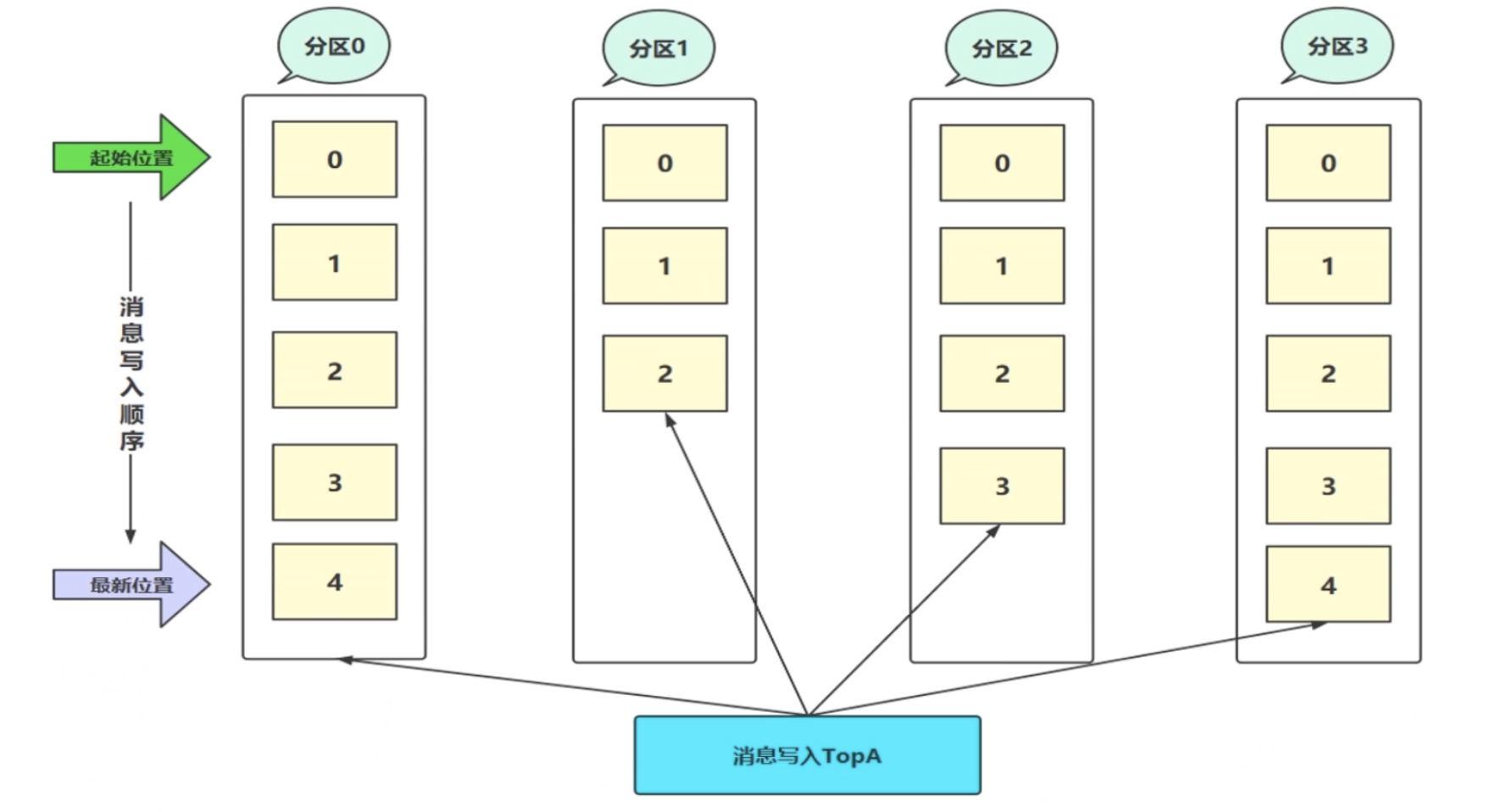
1.2.2 Topic、Partition
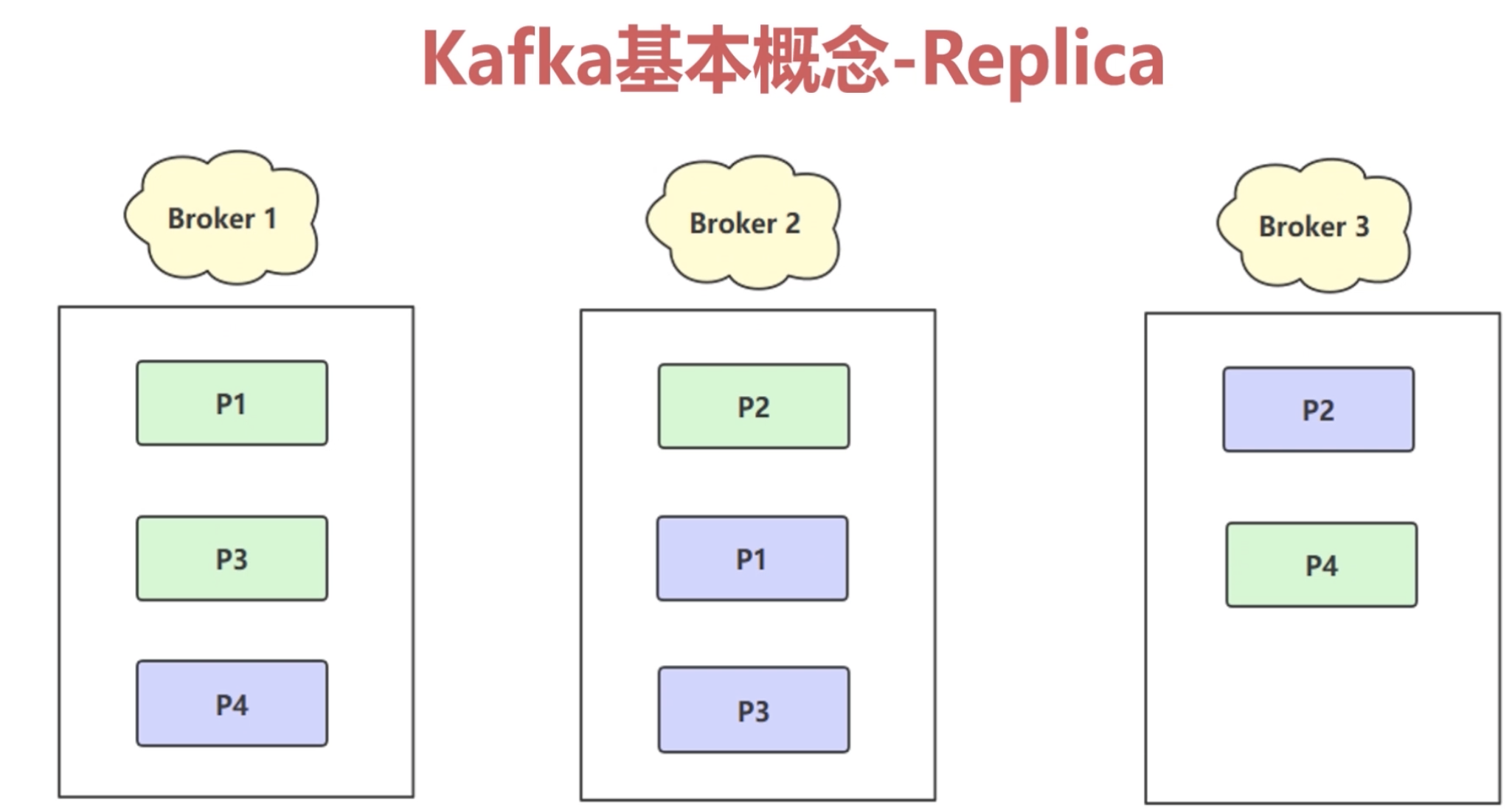
1.2.3 副本(replica)
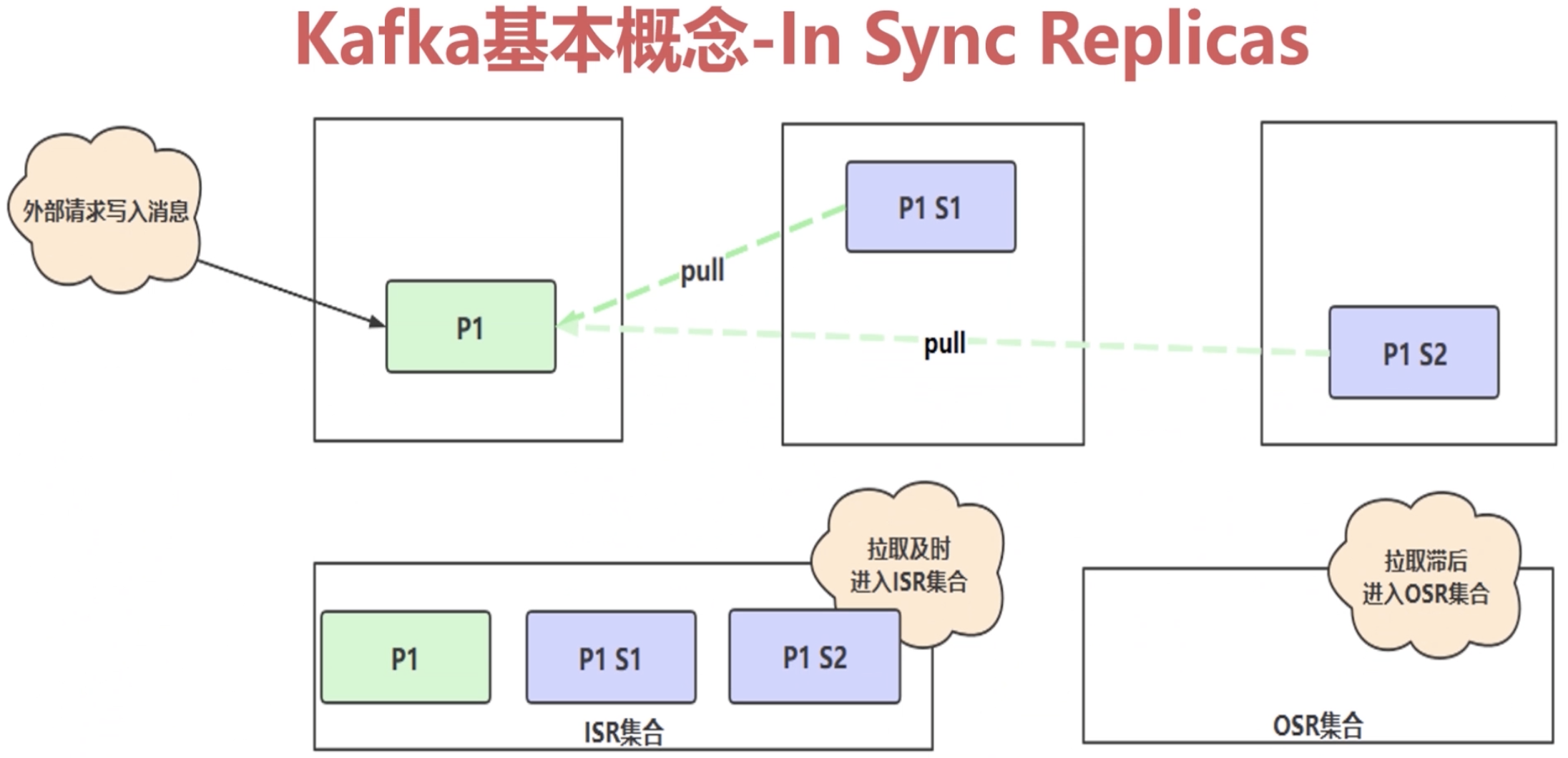
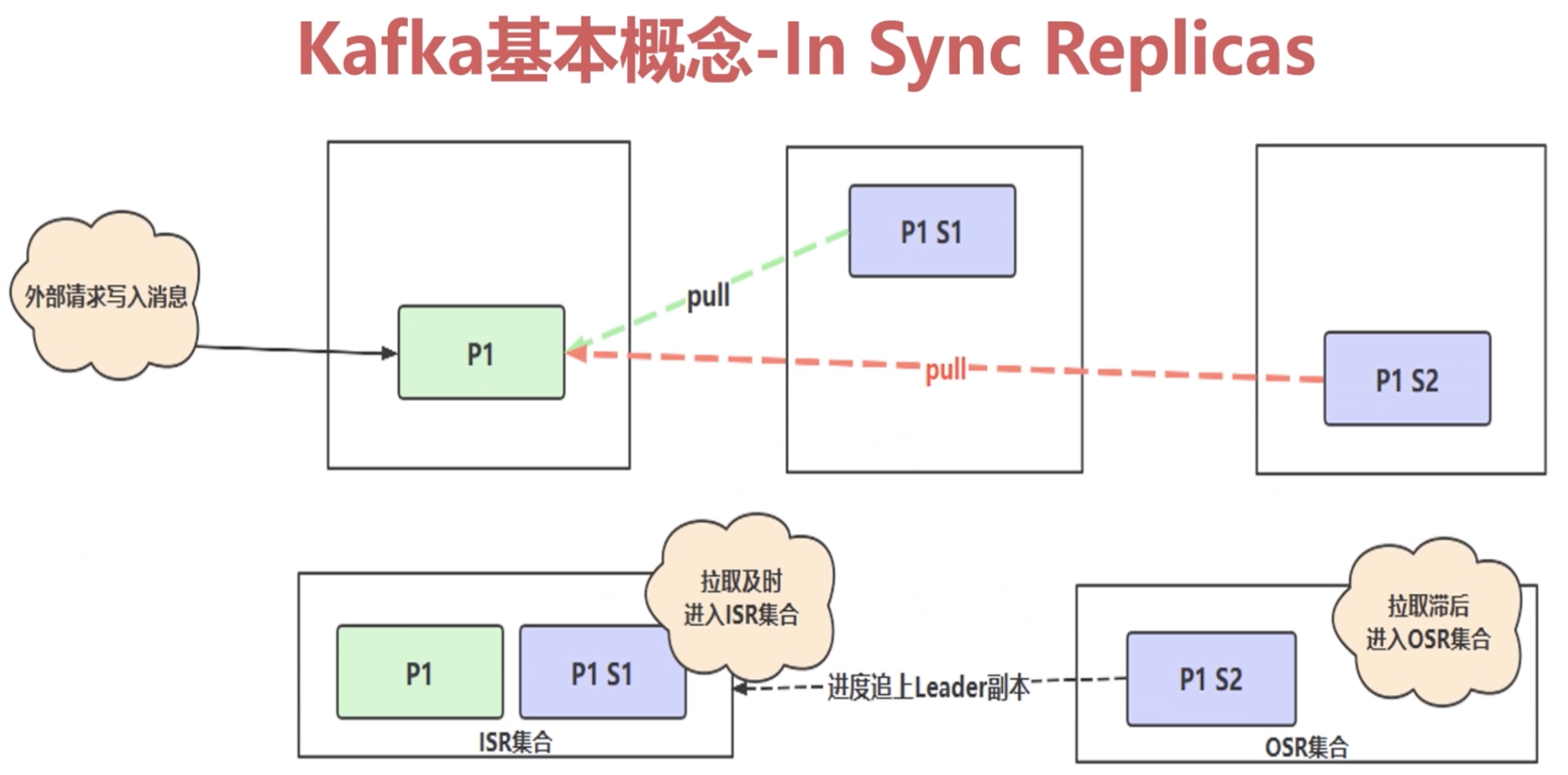
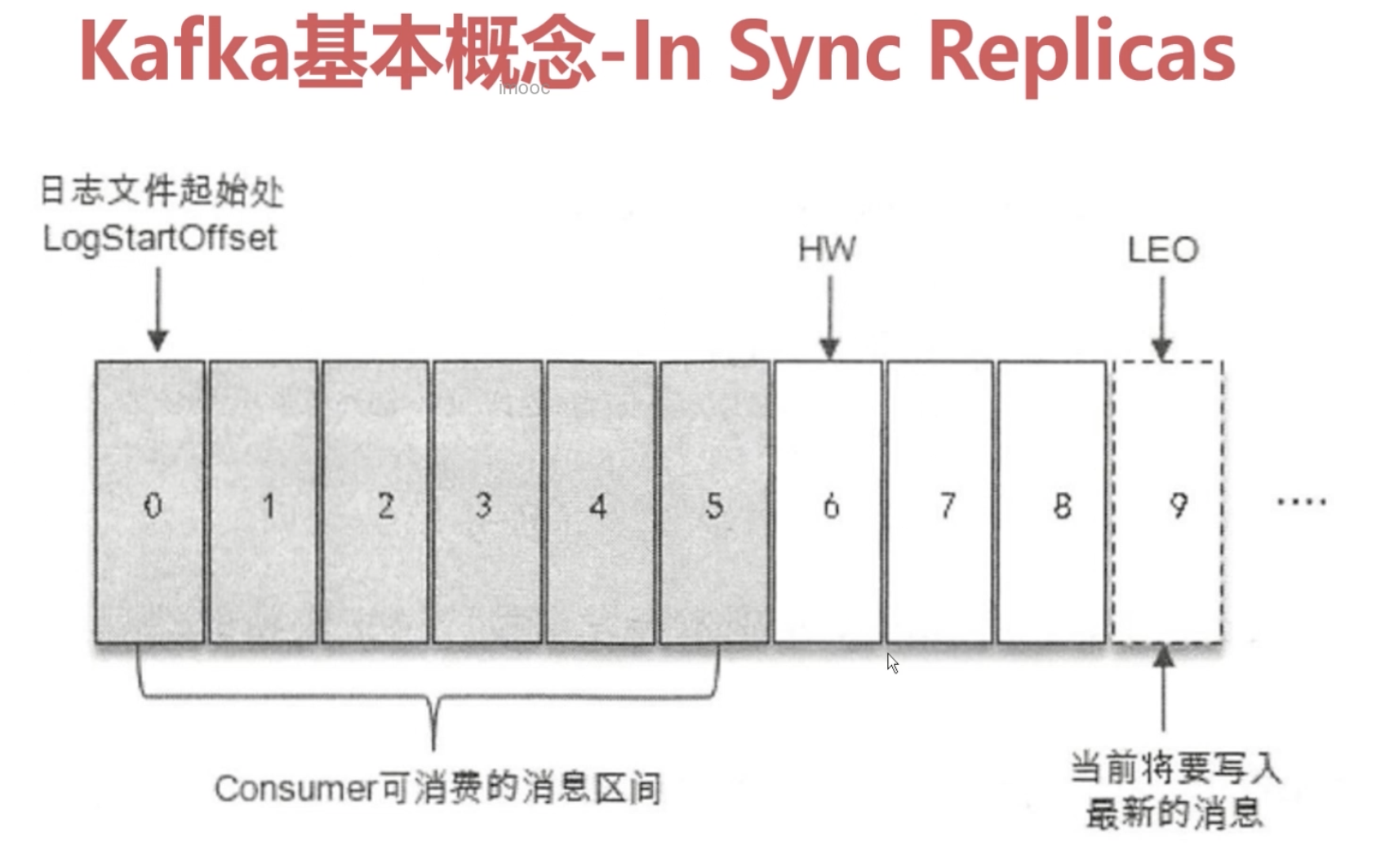
1.2.4 ISR详解(In Sync Replicas)
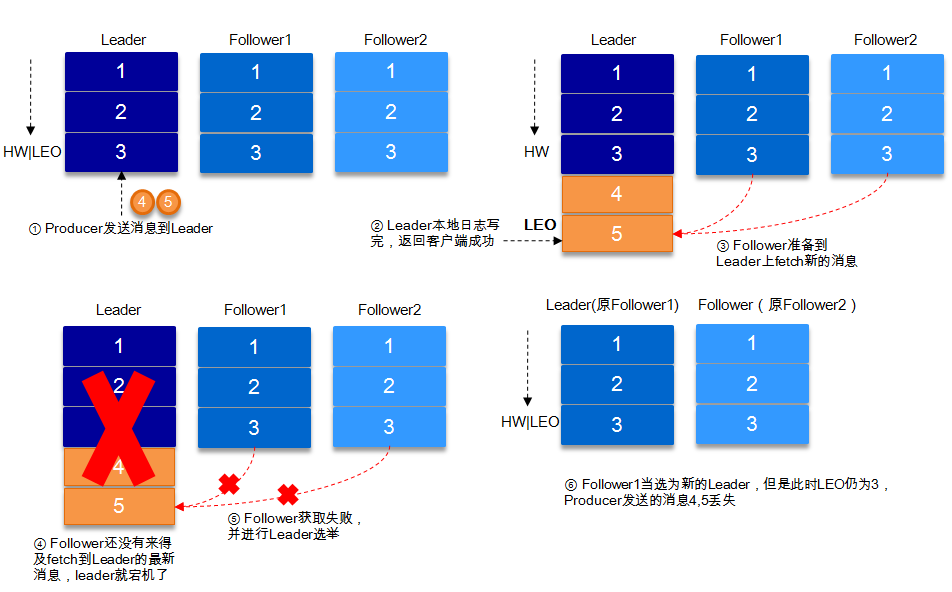
上图表示拉取及时的情况
上图表示拉取滞后的情况。
PS: 当Kafka集群中的 leader 挂了之后,Kafka集群会重新选举leader,这是只有在 ISR 集合里面的Kafka才会被选举成为leader。
HW: High Watermark, 高水位线,消费者只能最多拉取到高水位线的消息
LEO: Log End Offset,日志文件的最后一条记录的 offset(偏移量)
ISR 集合与 HW 和 LEO 直接存在着密不可分的关系
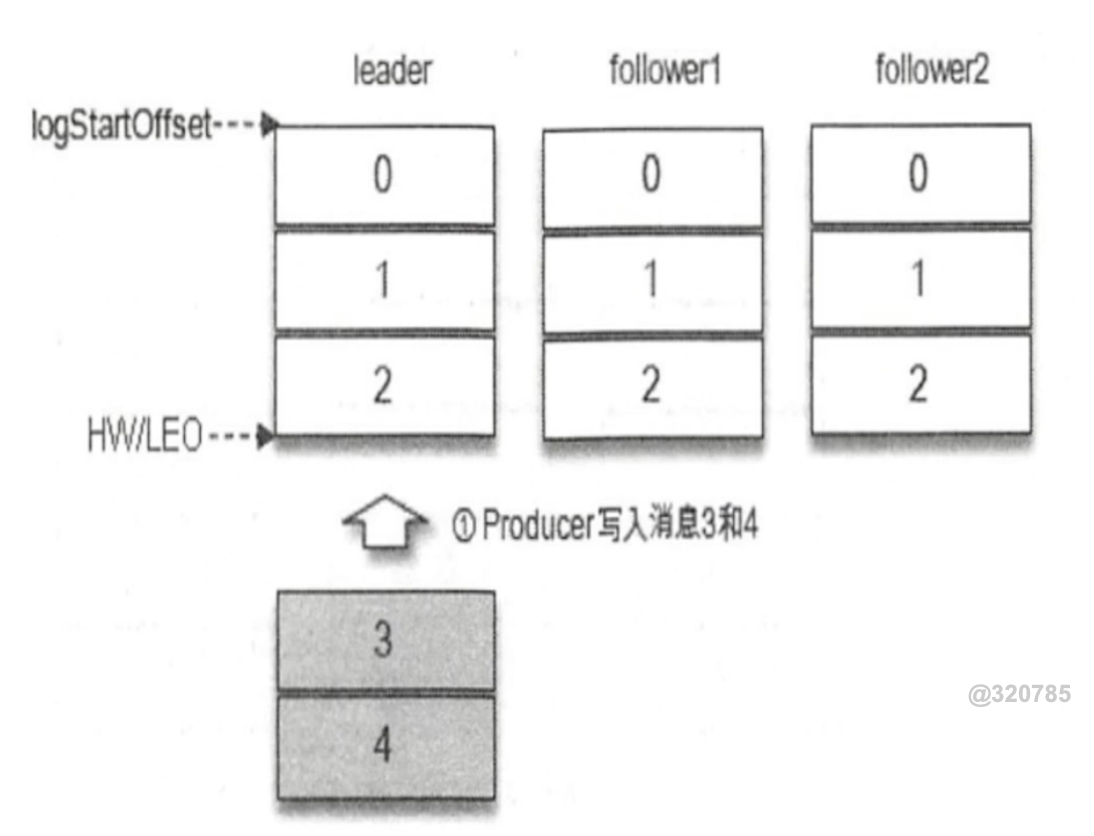
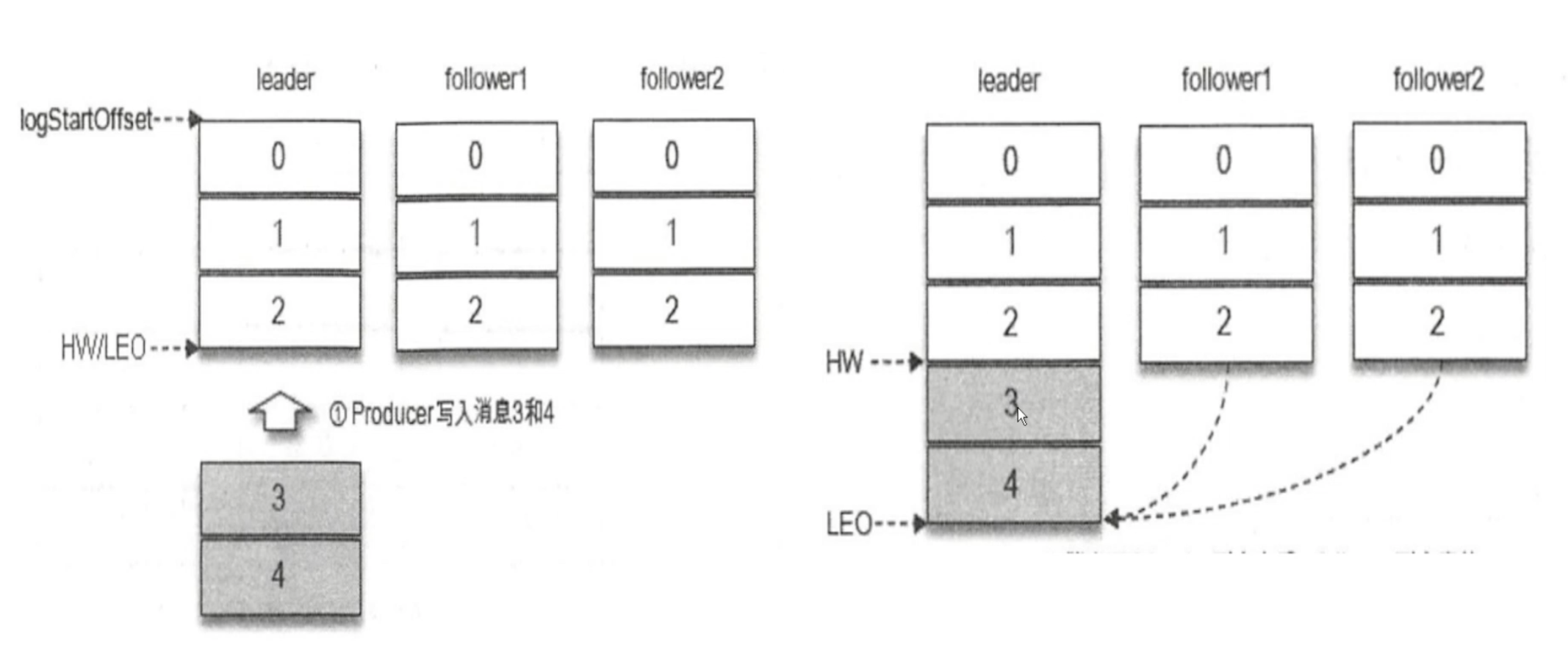
上图右边的图形表示数据传入到leader节点,但还没有同步到follower节点上
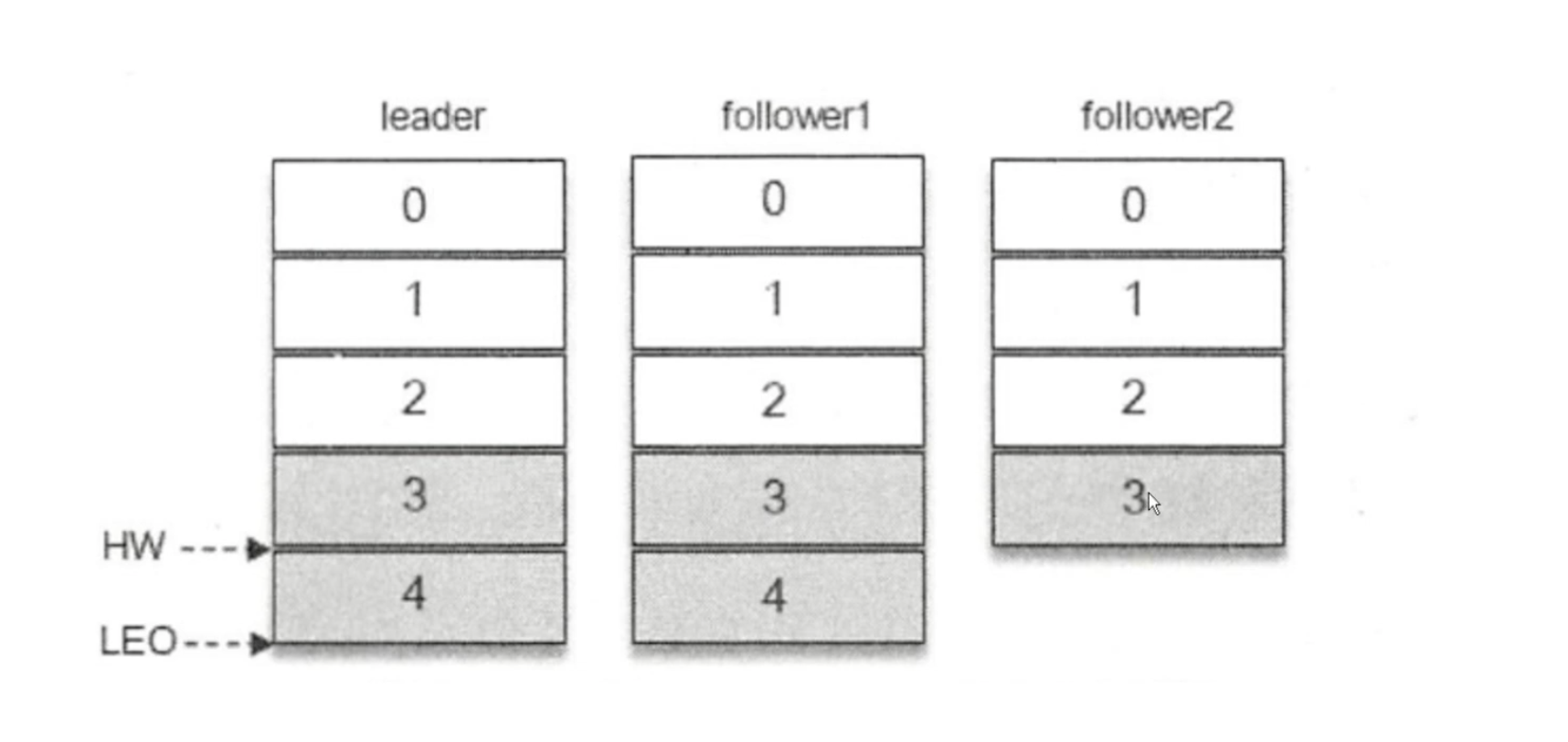
上图HW移动了一格,表示 follower1 节点和follower2 节点都同步了第3条数据,而第4条数据因为follower2节点没有同步到,Kafka消费者就消费不了第4条数据。
1.3 Kafka 环境搭建 zookeeper 集群搭建
Kafka 集群搭建
Kafka Manager - Kafka集群管理工具 kafka 命令行工具常用命令行操作
1.4 Kafka 极速入门 1.4.1 构建生产者步骤
配置生产者参数属性和创建生产者对象
构建消息:ProducerRecord
发送消息
关闭生产者
1.4.2 构建消费者步骤
配置消费者参数属性和创建消费者对象
订阅主题
拉取消息并进行消费处理
提交消费偏移量,关闭消费者
1.4.3 代码实现 1.4.3.1 配置类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 @Configuration public class KafkaConfig @Bean public KafkaProducer<String, String> producerRecord () Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093" ); properties.setProperty(ProducerConfig.ACKS_CONFIG, "all" ); properties.setProperty(ProducerConfig.RETRIES_CONFIG, "3" ); properties.setProperty(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, "100" ); properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, "16348" ); properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "10" ); properties.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554432" ); properties.setProperty(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, "com.xiaolyuh.interceptor.TraceInterceptor" ); Serializer<String> keySerializer = new StringSerializer(); Serializer<String> valueSerializer = new StringSerializer(); return new KafkaProducer<>(properties, keySerializer, valueSerializer); } }
1.4.3.2 生产者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 @RunWith(SpringRunner.class) @SpringBootTest public class SpringBootStudentKafkaApplicationTests @Autowired private KafkaProducer<String, String> kafkaProducer; @Test public void testSyncKafkaSend () throws Exception for (int i = 0 ; i < 100 ; i++) { ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test_cluster_topic" , "key-" + i, "value-" + i); kafkaProducer.send(producerRecord, new KafkaCallback<>(producerRecord)).get(50 , TimeUnit.MINUTES); } System.out.println("ThreadName::" + Thread.currentThread().getName()); } @Test public void testAsyncKafkaSend () for (int i = 0 ; i < 100 ; i++) { ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test_cluster_topic2" , "key-" + i, "value-" + i); kafkaProducer.send(producerRecord, new KafkaCallback<>(producerRecord)); } System.out.println("ThreadName::" + Thread.currentThread().getName()); kafkaProducer.flush(); } } class KafkaCallback <K , V > implements Callback private final ProducerRecord<K, V> producerRecord; public KafkaCallback (ProducerRecord<K, V> producerRecord) this .producerRecord = producerRecord; } @Override public void onCompletion (RecordMetadata metadata, Exception exception) System.out.println("ThreadName::" + Thread.currentThread().getName()); if (Objects.isNull(exception)) { System.out.println(metadata.partition() + "-" + metadata.offset() + ":::" + producerRecord.key() + "=" + producerRecord.value()); } if (Objects.nonNull(exception)) { } } }
1.4.3.3 消费者 Kafka中的消息消费是一个不断轮询的过程,消费者所要做的就是重复地调用poll()方法,而poll()方法返回的是所订阅的主题(分区)上的一组消息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 @Component public class KafkaConsumerDemo ThreadPoolExecutor executor = new ThreadPoolExecutor(1 , 10 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(1 )); @PostConstruct public void startConsumer () executor.submit(() -> { Properties properties = new Properties(); properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093" ); properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "groupId" ); properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false" ); properties.setProperty(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, "60000" ); Deserializer<String> keyDeserializer = new StringDeserializer(); Deserializer<String> valueDeserializer = new StringDeserializer(); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties, keyDeserializer, valueDeserializer); consumer.subscribe(Arrays.asList("test_cluster_topic" )); Set<TopicPartition> assignment = consumer.assignment(); while (assignment.isEmpty()) { consumer.poll(1000 ); assignment = consumer.assignment(); } while (true ) { ConsumerRecords<String, String> records = consumer.poll(1000 ); for (ConsumerRecord<String, String> record : records) { String traceId = new String(record.headers().lastHeader("traceId" ).value()); System.out.printf("traceId = %s, offset = %d, key = %s, value = %s%n" , traceId, record.offset(), record.key(), record.value()); } consumer.commitAsync((offsets, exception) -> { if (Objects.isNull(exception)) { } }); } }); } }
1.4.3.4 拦截器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public class TraceInterceptor implements ProducerInterceptor <String , String > private int errorCounter = 0 ; private int successCounter = 0 ; @Override public void configure (Map<String, ?> configs) System.out.println(JSON.toJSONString(configs)); } @Override public ProducerRecord<String, String> onSend (ProducerRecord<String, String> record) Headers headers = new RecordHeaders(); headers.add("traceId" , UUID.randomUUID().toString().getBytes(Charset.forName("UTF8" ))); return new ProducerRecord<>(record.topic(), record.partition(), record.key(), record.value(), headers); } @Override public void onAcknowledgement (RecordMetadata metadata, Exception exception) if (Objects.isNull(exception)) { } } @Override public void close () System.out.println("==========close============" ); } }
1.5 Kafka 基本配置参数讲解
1.6 Kafka 之生产者 1.6.1 发送消息:ProducerRecord 1 2 3 4 5 6 7 8 9 public class ProducerRecord <K , V > private final String topic; private final Integer partition; private final Headers headers; private final K key; private final V value; private final Long timestamp; }
PS: 一条消息会通过 Key 去计算出来实际的 partition,按照 partitiion 去存储的。
1.6.2 必要的参数配置项
bootstrap.servers:逗号分隔符,多个地址,防止单点故障
key.serializer, value.serializer:kafka实际发送的是二进制的内容,所以必须序列化
client.id:kafka 对应生产者的ID。如果不设置,Kafka 内部会自动生成一个非空字符串
简化的配置Key: ProducerConfig
KafkaProducer 是线程安全的(kafka消费者不是线程安全的)
1.6.3 发送消息的3种方法
Kafka 发送消息提供了 3 种方法:
sendOffsetsToTransaction: 事务相关
send(ProducerRecord<K,V>):Future:异步,但是使用 Future.get()方法相当于同步
send(ProducerRecord<K,V>, Callback):Future:异步,返回值会放到 Callback 回调函数里
1.6.4 KafkaProducer 消息发送重试机制
retries 参数
可重试异常(例如:网络抖动) & 不可重试异常(例如:磁盘满了、消息体积太大)
1.7 Kafka 之生产者重要参数详解
acks: 指定发送消息后,Broker端至少有多少个副本接收到该消息;默认 acks = 1;(Broker端只要主分区写入成功,就可以给客户端去回送响应,如果leader宕机了,则会丢失数据 )
acks = 0:生产者发送消息之后不需要等待任何服务端的响应;(这种情况下数据传输效率最高,但是数据可靠性确是最低的。)
acks = -1 或者 acks=all:生产者在发送消息之后,需要等待 ISR 中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应。
你以为这样就能保证数据不丢失了吗?例如当ISR中的成员只有leader的时候,就相当于 acks=1 了。
那么该怎么样保证数据的可靠性能?还需要min.insync.replicas这个参数(可以在broker或者topic层面进行设置)的配合,这样才能发挥最大的功效。
min.insync.replicas这个参数设定ISR中的最小副本数是多少,默认值为1,当且仅当request.required.acks参数设置为-1时,此参数才生效。
如果ISR中的副本数少于min.insync.replicas配置的数量时,客户端会返回异常:org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required。
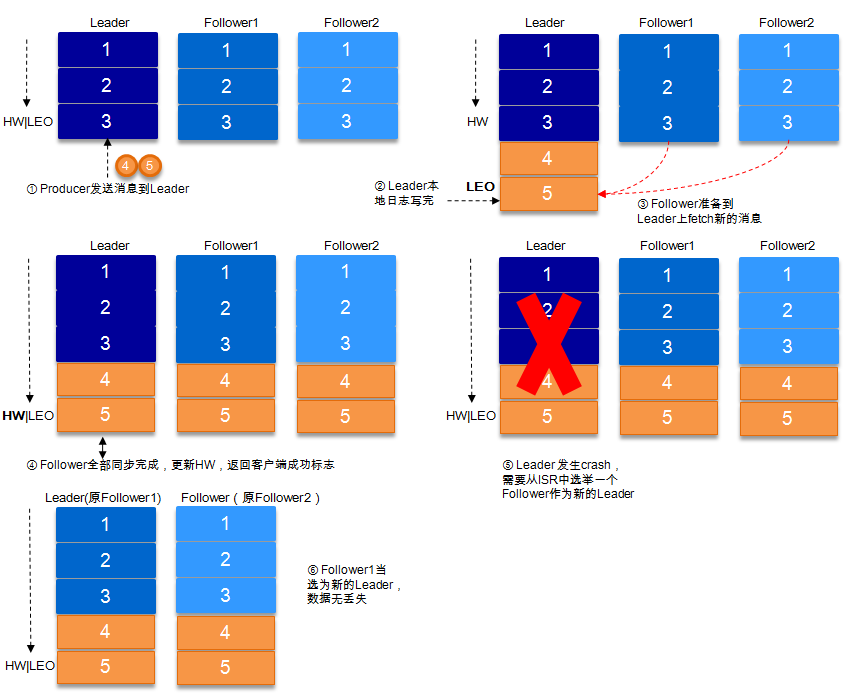
ISR中的flower全部完成数据同步后,leader此时挂掉,会重新选举leader,数据不会丢失。
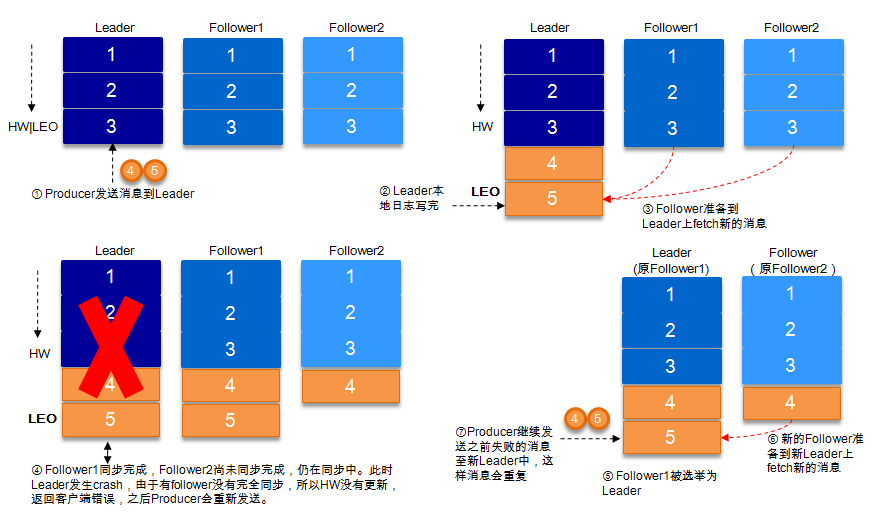
数据发送到leader后 ,部分ISR的副本同步,leader此时挂掉。比如follower1和follower2都有可能变成新的leader, producer端会得到返回异常,producer端会重新发送数据,数据可能会重复。
max.request.size:该参数用来限制生产者客户端能发送的消息的最大值,默认 1M(10485768)
retries 和 retry.backoff.msretries: 重试次数和重试间隔,默认100
compression.type: 这个参数用来指定消息的压缩方式,默认值为 none , 可选配置:gzip,snappy 和 lz4
connections.max.idle.ms:这个参数用来指定在多久之后关闭限制的连接,默认值是54000ms,即9分钟
linger.ms:这个参数用来指定生产者发送 ProducerBatch 之前等待更多消息(ProducerRecord)加入ProducerBatch的时间,默认值为0
batch.size:累计多少条消息,则一次进行批量发送
buffer.memory:缓存提升性能参数,默认 32 M
receive.buffer.bytes: 这个参数用来设置Socket接受消息缓冲区(SO_RECBUF)的大小,默认值为32678(B),即32KB
send.buffer.bytes: 这个参数用来设置Socket发送消息缓存区(SO_SNDBUF)的大小,默认值为131072(B),即128KB。
request.timeout.ms: 这个参数用来配置Producer等待请求响应的最长时间,默认值为 3000 ms
1.8 Kafka 之拦截器 拦截器(interceptor):Kafka对应着有生产者和消费者两种拦截器
生产者实现接口:org.apache.kafka.clients.producer.ProducerInterceptor
消费者实现接口:org.apache.kafka.clients.consumer.ConsumerInterceptor
1.9 Kafka 之序列化和反序列化
序列化反序列化:生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送Kafka;而在对侧,消费者需要用反序列化器(Derializer)把从Kafka中收到的字节数组转换成相应的对象。
序列化接口:org.apache.kafka.common.serialization.Serializer
除了用于String类型的序列化器之外还有:ByteArray、ByteBuffer、Bytes、Double、Integer、Long这几种类型,它们都实现了org.apache.kafka.common.serialization.Serializer接口,此接口有三种方法:
public void configure(Map<String, ?> configs, boolean isKey):用来配置当前类。
public byte[] serialize(String topic, T data):用来执行序列化。
public void close():用来关闭当前序列化器。一般情况下这个方法都是个空方法,如果实现了此方法,必须确保此方法的幂等性,因为这个方法很可能会被KafkaProducer调用多次。
如何自定义序列化?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 @Data public class User private String id; private String name; } public class UserSerializer implements Serializer <User > public void configure (Map<String, ?> configs, boolean isKey) public byte [] serialize(String topic, User data) { if (data == null ) { return null ; } byte [] id, name; try { if (data.getId() != null ) { id = data.getId().getBytes("UTF-8" ); } else { name = new byte [0 ]; } if (data.getName() != null ) { name = data.getName().getBytes("UTF-8" ); } else { name = new byte [0 ]; } ByteBuffer buffer = ByteBuffer.allocate(4 +4 +id.length + name.length); buffer.putInt(id.length); buffer.put(id); buffer.putInt(name.length); buffer.put(name); return buffer.array(); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } return new byte [0 ]; } public void close () } properties.put("value.serializer" , "com.examples.fengxuechao.UserSerializer" ); Producer<String,User> producer = new KafkaProducer<String,User>(properties); User user = new User("1" , "Hi" ); ProducerRecord<String, User> producerRecord = new ProducerRecord<String, User>(topic,user);
反序列化接口:org.apache.kafka.common.serialization.Derializer
同接口同样有 3 个方法:
public void configure(Map<String, ?> configs, boolean isKey):用来配置当前类。
public byte[] serialize(String topic, T data):用来执行反序列化。如果data为null建议处理的时候直接返回null而不是抛出一个异常。
public void close():用来关闭当前序列化器。
如何反序列化?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class UserDeserializer implements Deserializer <User > public void configure (Map<String, ?> configs, boolean isKey) public User deserialize (String topic, byte [] data) if (data == null ) { return null ; } if (data.length < 8 ) { throw new SerializationException("Size of data received by UserDeserializer is shorter than expected!" ); } ByteBuffer buffer = ByteBuffer.wrap(data); int idLen, nameLen; String id, name; idLen = buffer.getInt(); byte [] idBytes = new byte [idLen]; buffer.get(idBytes); nameLen = buffer.getInt(); byte [] nameBytes = new byte [nameLen]; buffer.get(nameBytes); try { id = new String(idBytes, "UTF-8" ); name = new String(nameBytes, "UTF-8" ); } catch (UnsupportedEncodingException e) { throw new SerializationException("Error occur when deserializing!" ); } return new User(name,address); } public void close () }
其实序列化完全可以和Avro、ProtoBuf等联合使用,而且更加的方便快捷。不过,如无必要,用默认的String序列化就可以了(使用自定义的序列化就不容易变了,如User类要添加一个属性)。
1.10 Kafka 之分区器
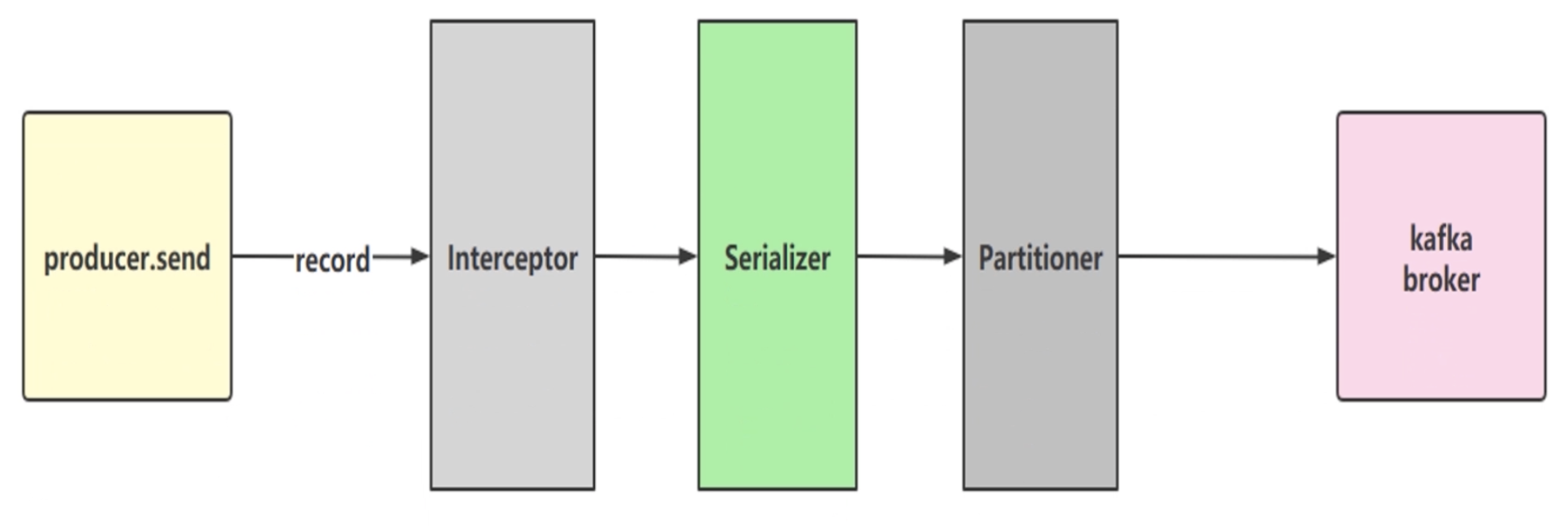
上图是生产者发送消息后会经历一系列的过程:
生产者发送消息
拦截器
序列化
分区:如果消息中没有指定分区,就会使用分区器
到达Broker
生产者消息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class ProducerRecord <K , V > private final String topic; private final Integer partition; private final Headers headers; private final K key; private final V value; private final Long timestamp; }
org.apache.kafka:kafka-clients:2.0.1中的 KafkaProducer 的partition源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 private int partition (ProducerRecord<K, V> record, byte [] serializedKey, byte [] serializedValue, Cluster cluster) Integer partition = record.partition(); return partition != null ? partition : partitioner.partition( record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); }
可以看出的确是先判断有无指明ProducerRecord的partition字段,如果没有指明,则再进一步计算分区。上面这段代码中的partitioner在默认情况下是指Kafka默认实现的org.apache.kafka.clients.producer.DefaultPartitioner,其源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 public class DefaultPartitioner implements Partitioner private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>(); public void configure (Map<String, ?> configs) public int partition (String topic, Object key, byte [] keyBytes, Object value, byte [] valueBytes, Cluster cluster) List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (keyBytes == null ) { int nextValue = nextValue(topic); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0 ) { int part = Utils.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { return Utils.toPositive(nextValue) % numPartitions; } } else { return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } } private int nextValue (String topic) AtomicInteger counter = topicCounterMap.get(topic); if (null == counter) { counter = new AtomicInteger(ThreadLocalRandom.current().nextInt()); AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter); if (currentCounter != null ) { counter = currentCounter; } } return counter.getAndIncrement(); } public void close () }
由上源码可以看出partition的计算方式:
如果key为null,则按照一种轮询的方式来计算分区分配
如果key不为null则使用称之为murmur的Hash算法(非加密型Hash函数,具备高运算性能及低碰撞率)来计算分区分配。
当然我们也可自定义自己的分区器,如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class UserPartitioner implements Partitioner private final AtomicInteger atomicInteger = new AtomicInteger(0 ); @Override public void configure (Map<String, ?> configs) @Override public int partition (String topic, Object key, byte [] keyBytes, Object value, byte [] valueBytes, Cluster cluster) List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (null == keyBytes || keyBytes.length<1 ) { return atomicInteger.getAndIncrement() % numPartitions; } int hash = 0 ; for (byte b : keyBytes) { hash = 31 * hash + b; } return hash % numPartitions; } @Override public void close () }
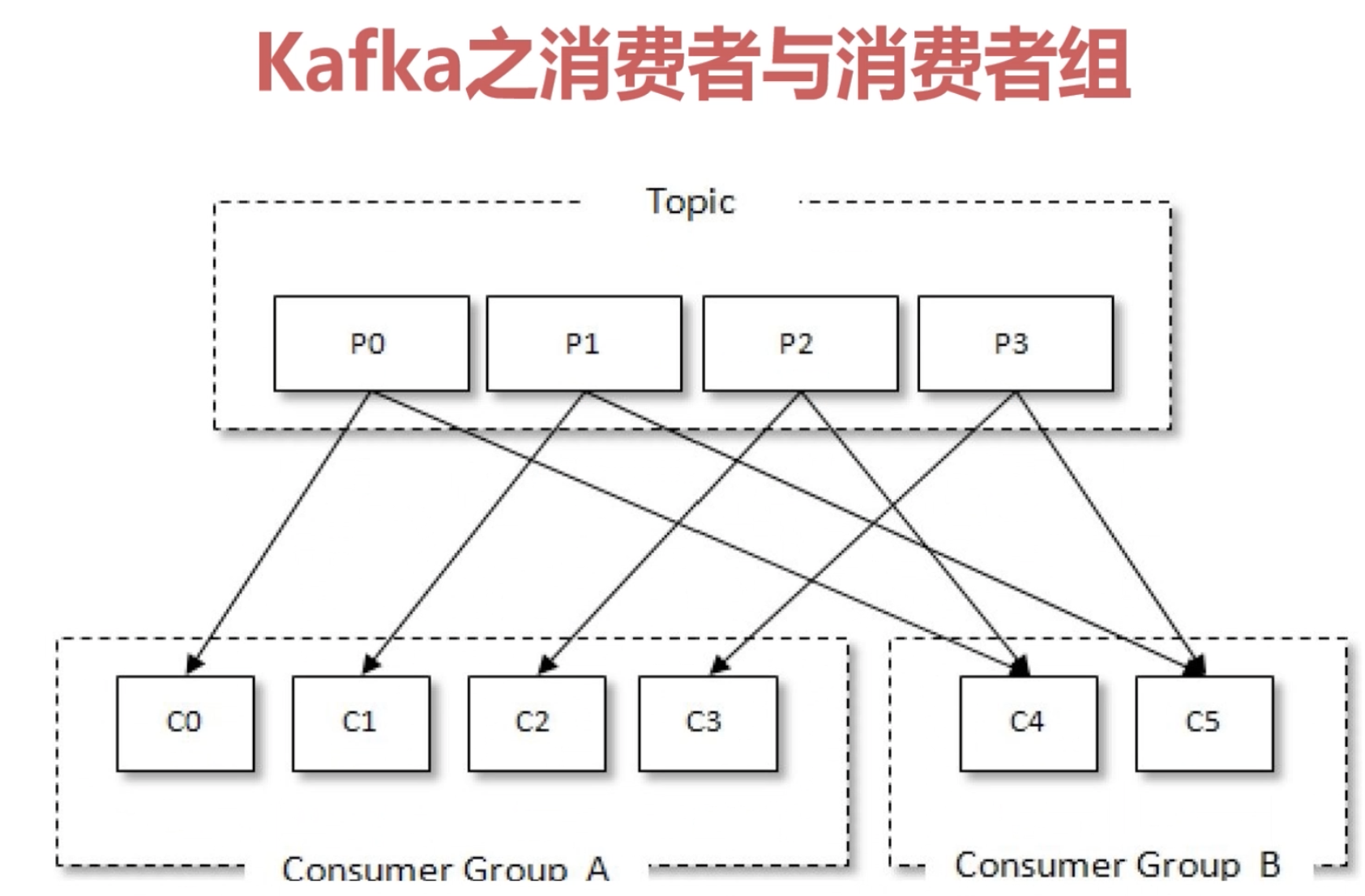
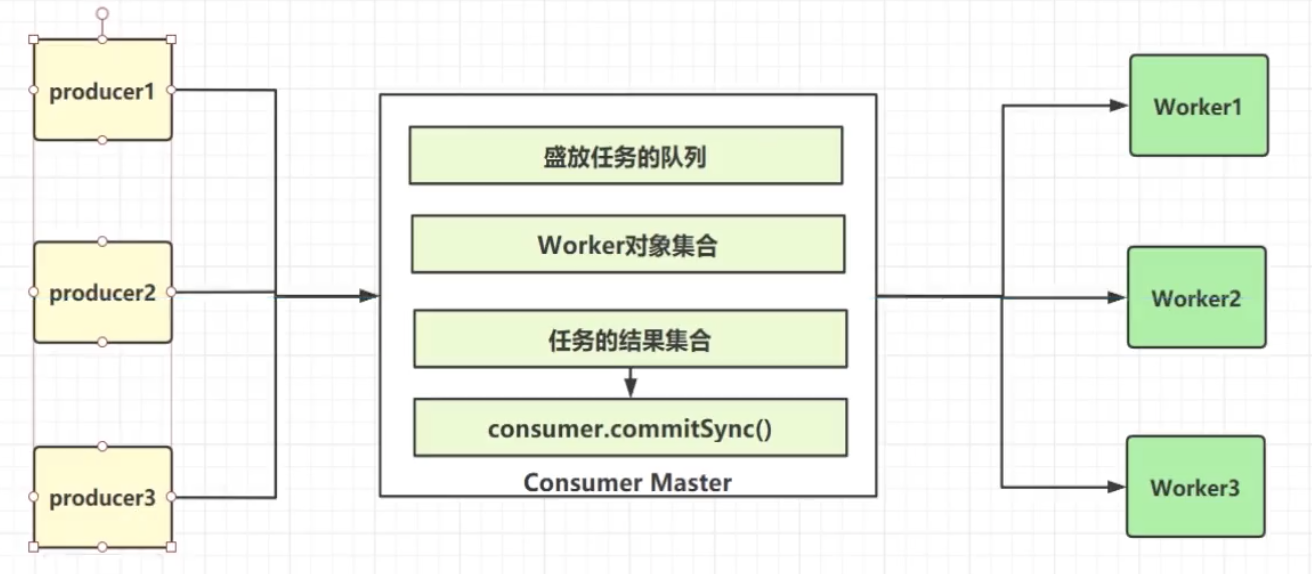
1.11 Kafka 之消费者与消费者组 1.11.1 概念
说明:
一个Topic可以有多个分区
一个主题可以有多个消费者组
一个消费者组可以有多个消费者,一个消费者只能属于一个消费者组
每一个分区可以被多个消费者组消费,每一个分区只能被一个消费者组中的一个消费者所消费,详见下图
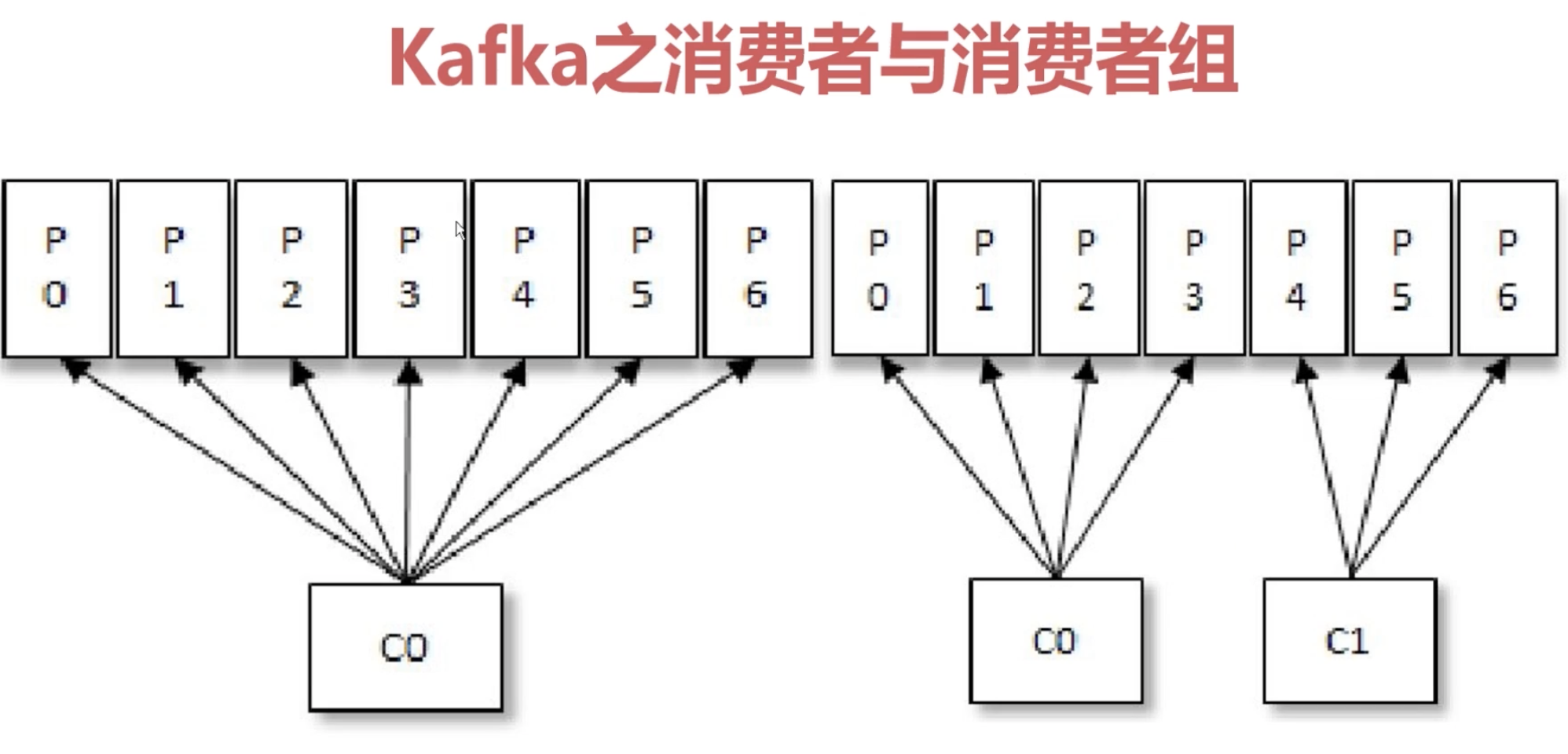
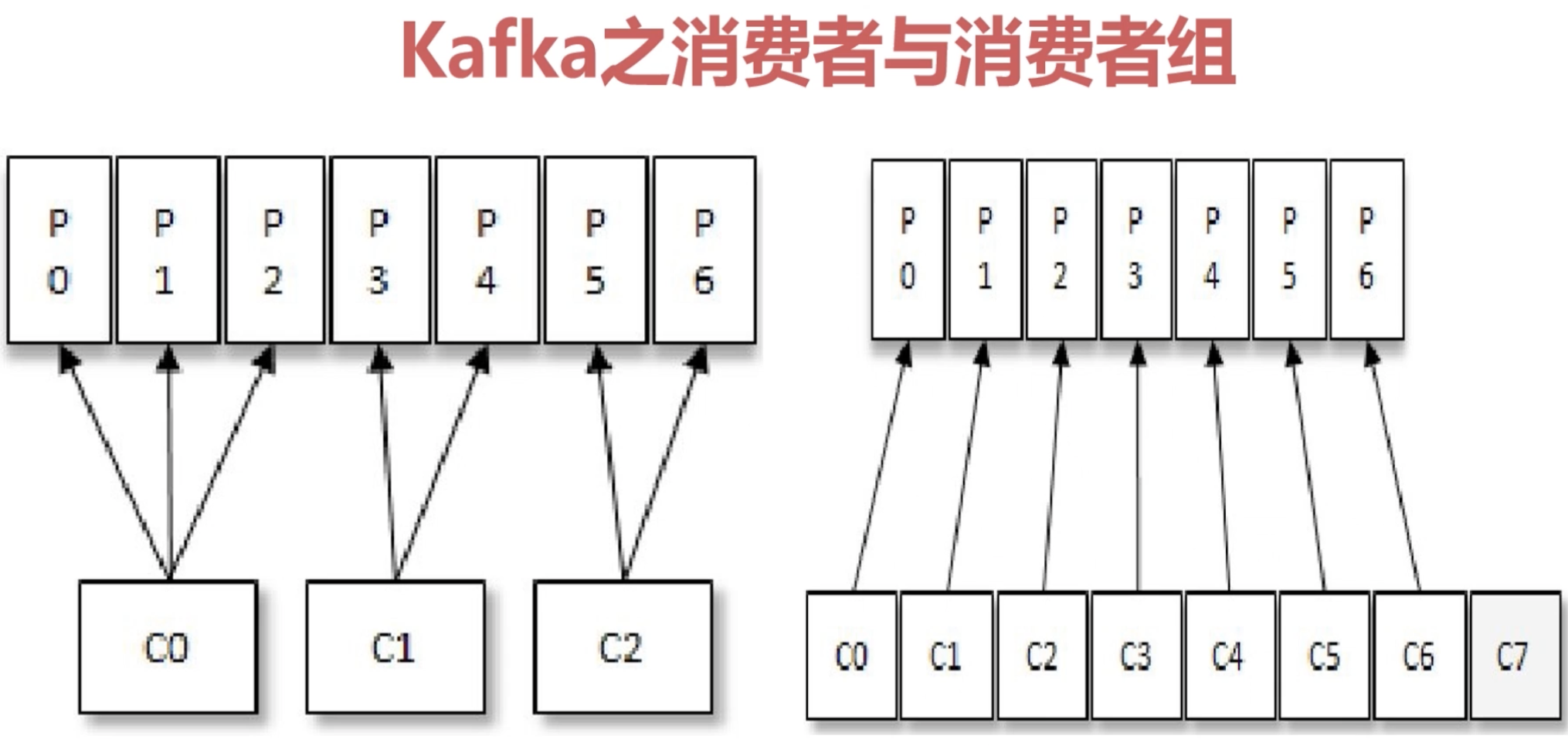
一个消费者组内的消费者数量多于分区时,多出来的消费者不做任何事。
1.11.2 消息中间件模型
点对点(P2P,Point-to-Point)模式
点对点模式是基于队列的,消息生产者发送消息到队列,消息消费者从队列接受消息。
发布/订阅(Pub/Sub)模式
发布/订阅模式定义了如何向一个内容节点发布和订阅消息,这个内容节点成为主题(Topic),主题可以认为是消息传递的中介,消息发布者将消息发布到某个主题,而消息订阅者从主题中订阅消息
Kafka同时支持两种消息投递模式,而这正是得益于消费者与消费者组模型的契合
所有的消费者都隶属于同一个消费组,相当于点对点模型
所有的消费者都隶属于不同的消费者组,相当于发布/订阅模型
1.11.3 Kafka 消费者必要参数方法
bootstrap.servers: 用来指定连接Kafka集群所需的broker地址清单
key.deserializer 和 value.deserializer: 反序列化参数
group.id: 消费者所属消费组
subscribe:消费主题订阅,支持集合/标准正则表达式
assign:只订阅主题的某个分区
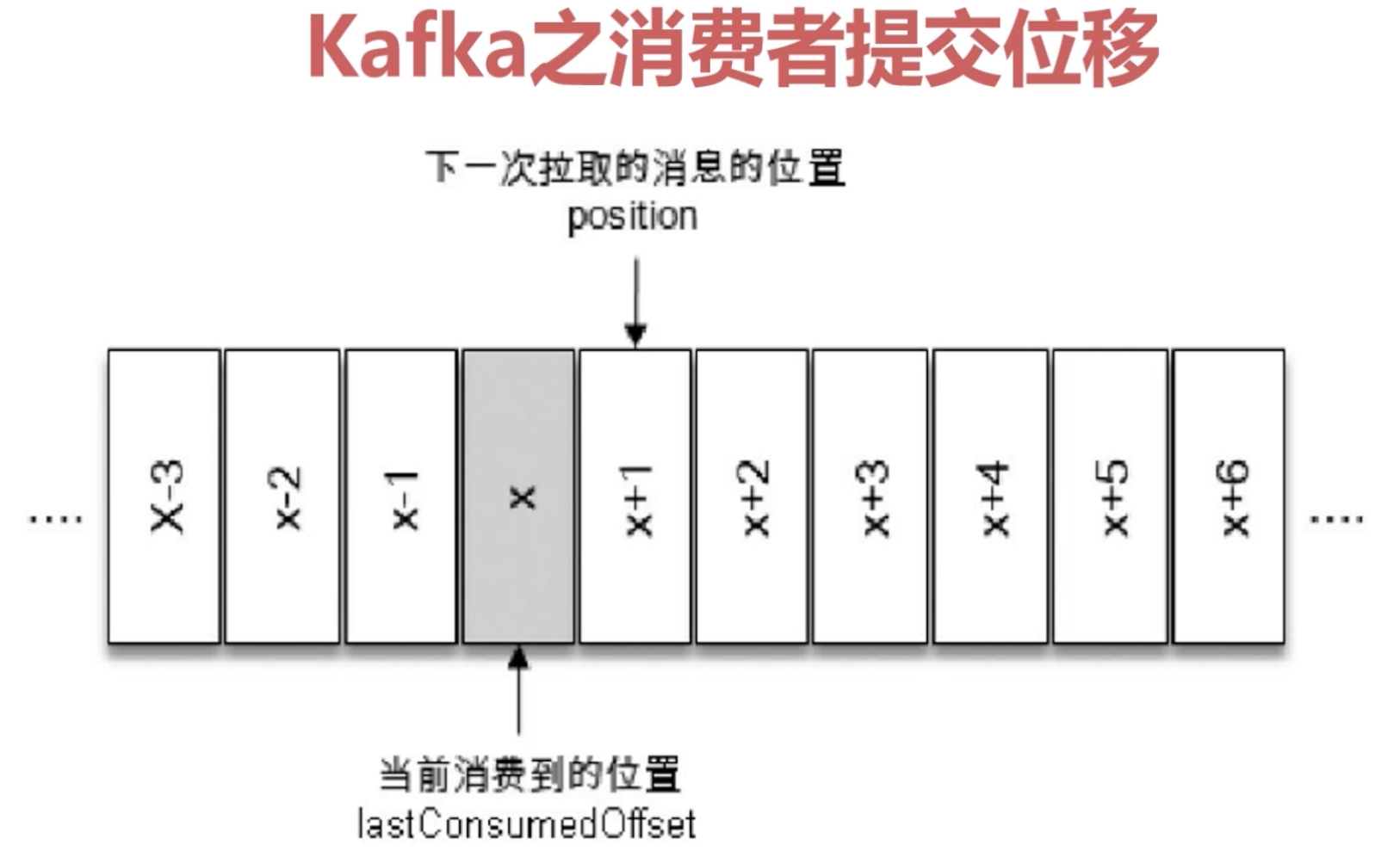
1.11.4 kafka 消费者提交位移
在实际的工作中一般采用手动提交位移的方式,这样会有比较好的容错性,我们会知道这条消息到底有没有消费成功,如果处理失败,那我们可以再次提交等兜底的策略。
Kafka 自动提交参数
- 自动提交:enable.auto.commit, 默认 true
- 提交周期间隔:auto.commit.interval.ms,默认值为 5 秒
手工提交参数
enable.auto.commit,配置为 false
提交方式:commitSync &commitAsync
同步提交:整体提交 & 分区提交
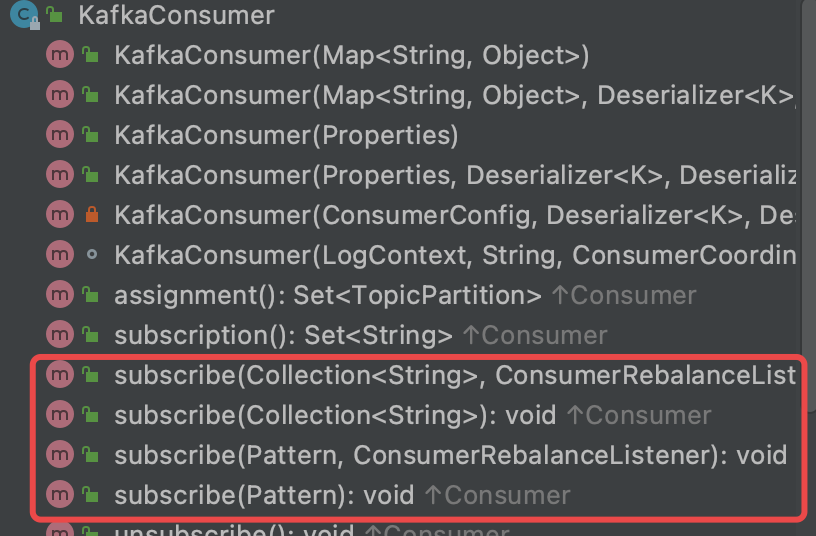
1.11.5 消费者subscribe 与 assign 详解
从上图中可以看到 subscribe 方法有 4 个重载的方法,对于 KafkaConsumer 消息的订阅,可以有多个主题,也可以支持正则表达式匹配。
假如我们只想要订阅一个 partition 呢?assign 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class PartitionInfo private final String topic; private final int partition; 分区 private final Node leader; private final Node[] replicas; private final Node[] inSyncReplicas; private final Node[] offlineReplicas; } public final class TopicPartition implements Serializable private int hash = 0 ; private final int partition; private final String topic; } # 拉取某个主题下的所有分区 List<PartitionInfo> tpInfoList = consumer.partitionsFor("topic" ) # 订阅主题为 topic 的 第 0 个分区,0 是从 PartitionInfo 中取来的 consumer.assign(Arrays.asList(new TopicPartition("topic" , 0 )))
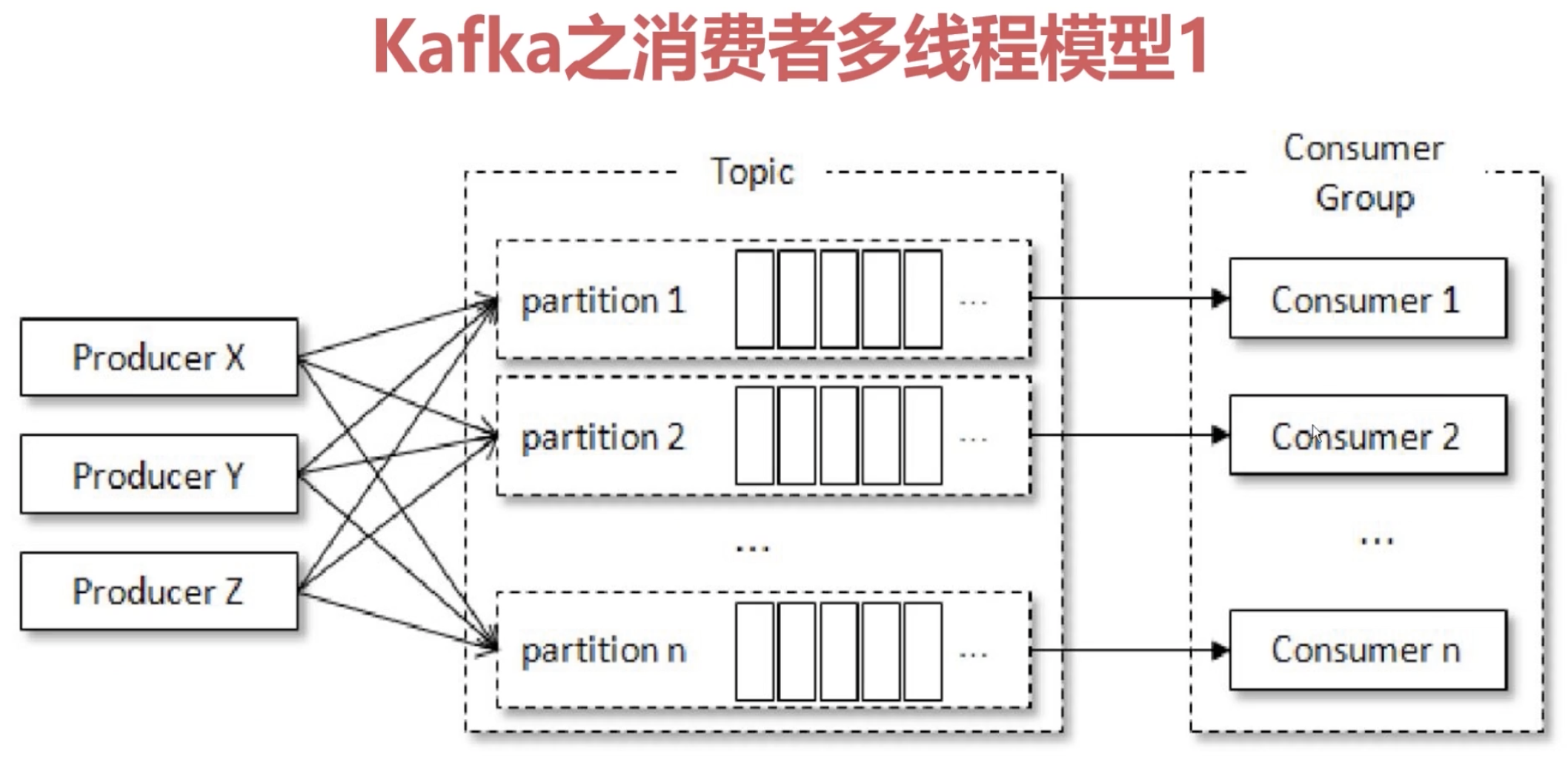
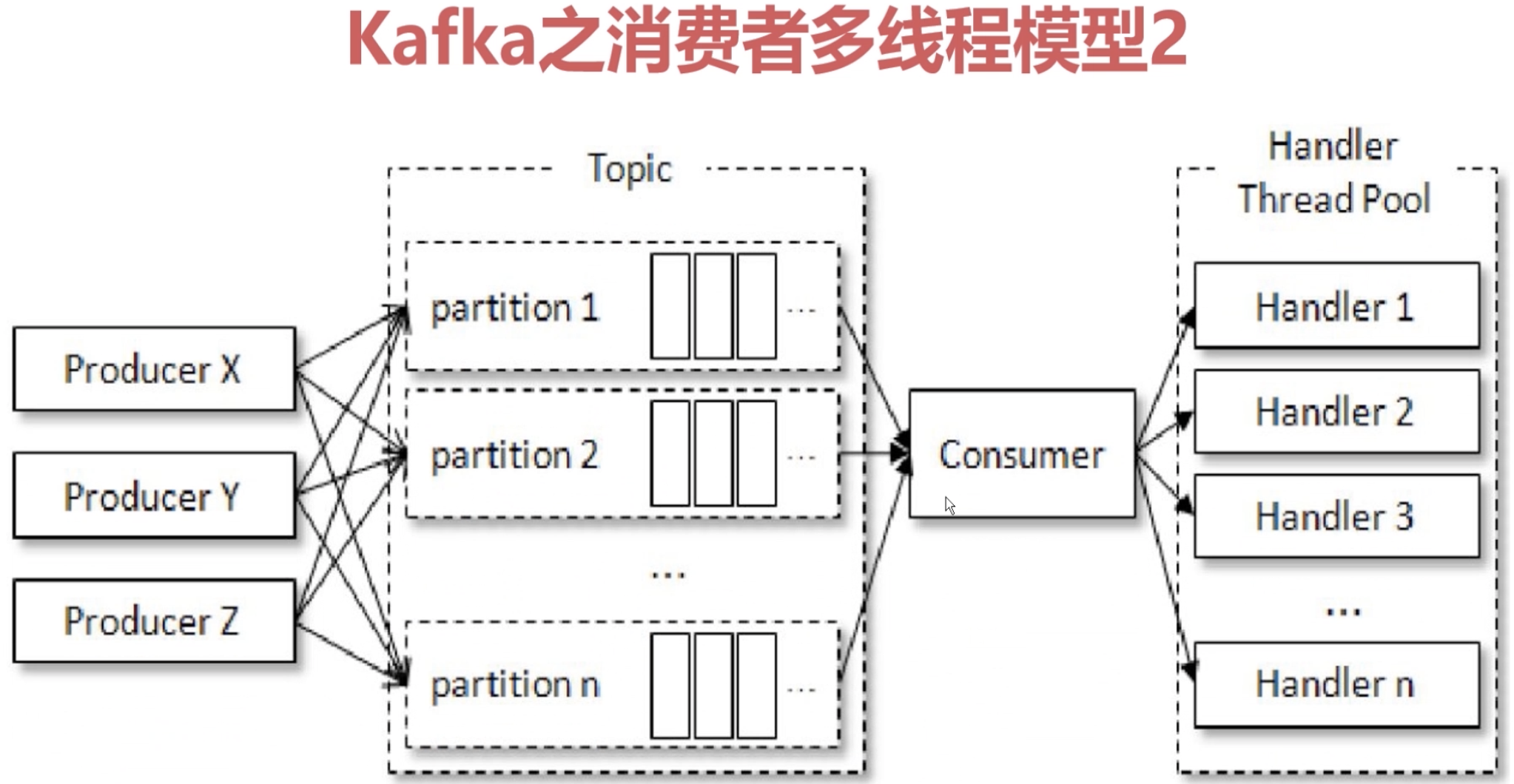
1.11.6 Kafka消费者之多线程
KafkaProducer 是线程安全的,但是KafkaConsumer却是线程非安全的
KafkaConsumer中定义了一个 acquire方法用来检测是否只有一个线程在操作,如果有其它线程操作则会抛出 ConcurrentModifactionException
KafkaConsumer在执行所有动作时都会先执行 acquire 方法检测是否线程安全
1.11.7 Kafka 消费者重要参数 性能调优参考
fetch.min.bytes: 一次拉取最小数据量,默认1B
fetch.max.bytes: 一次拉取最大数据量,默认50M
max.partition.fetch.bytes: 一次fetch请求,从一个partition中取得的records最大大小,默认1M
fetch.max.wait.ms: Fetch 请求发给broker后,在broker中可能会被阻塞的时长,默认500
fetch.poll.records: Consumer 每次调用 poll() 时取到的records的最大数,默认 500 条
1.12 Kafka 高级应用整合 Spring Boot
Maven配置
application.properties
创建KafkaTemplate对象
@KafkaListener 监听消息
1.12.1 核心依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 2.1.5.RELEASE</version > <relativePath /> </parent > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > org.springframework.kafka</groupId > <artifactId > spring-kafka</artifactId > </dependency > </dependencies >
1.12.2 生产者 application.properties 配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 spring.kafka.bootstrap-servers=localhost:9092 spring.kafka.producer.retries=0 spring.kafka.producer.batch-size=16384 spring.kafka.producer.buffer-memory=33554432 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.acks=1
1.12.3 KafkaProducerService 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Slf4j @Component public class KafkaProducerService @Autowired private KafkaTemplate<String, Object> kafkaTemplate; public void sendMessage (String topic, Object object) ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, object); future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() { @Override public void onSuccess (SendResult<String, Object> result) log.info("发送消息成功: " + result.toString()); } @Override public void onFailure (Throwable throwable) log.error("发送消息失败: " + throwable.getMessage()); } }); } }
1.12.4 消费者 application.properties 配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 spring.kafka.bootstrap-servers=192.168.11.51:9092 spring.kafka.consumer.enable-auto-commit=false spring.kafka.listener.ack-mode=manual spring.kafka.consumer.auto-offset-reset=earliest spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.listener.concurrency=5
1.12.5 KafkaConsumerService 1 2 3 4 5 6 7 8 9 10 11 @Slf4j @Component public class KafkaConsumerService { @KafkaListener(groupId = "group02", topics = "topic02") public void onMessage(ConsumerRecord<String, Object> record, Acknowledgment acknowledgment, Consumer<?, ?> consumer) { log.info("消费端接收消息: {}", record.value()); // 收工签收机制 acknowledgment.acknowledge(); } }
1.12.6 单元测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @RunWith(SpringRunner.class) @SpringBootTest public class ApplicationTests @Autowired private KafkaProducerService kafkaProducerService; @Test public void send () throws InterruptedException String topic = "topic02" ; for (int i=0 ; i < 1000 ; i ++) { kafkaProducerService.sendMessage(topic, "hello kafka" + i); Thread.sleep(5 ); } } }
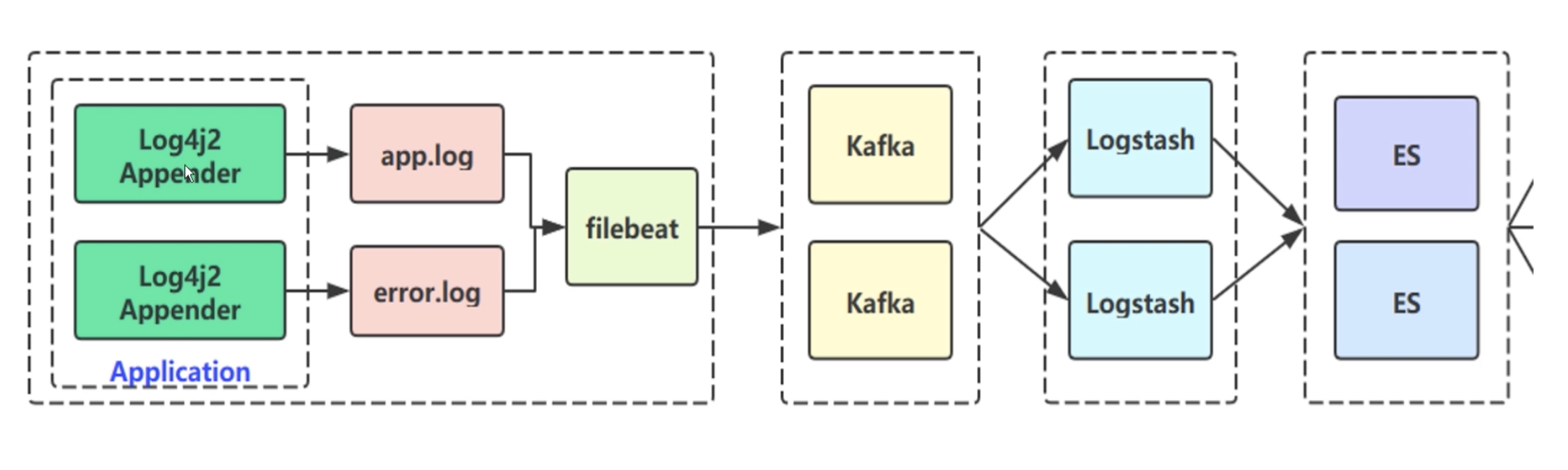
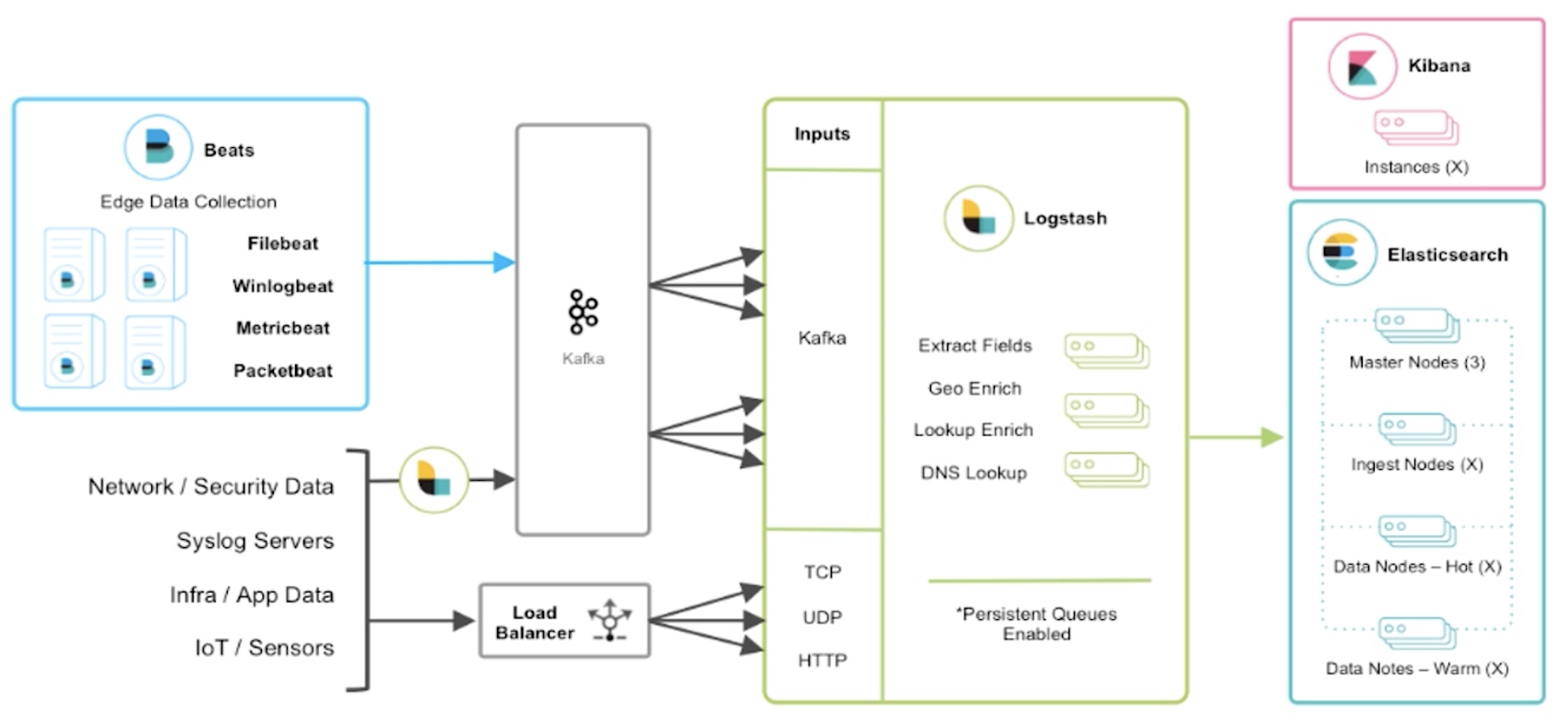
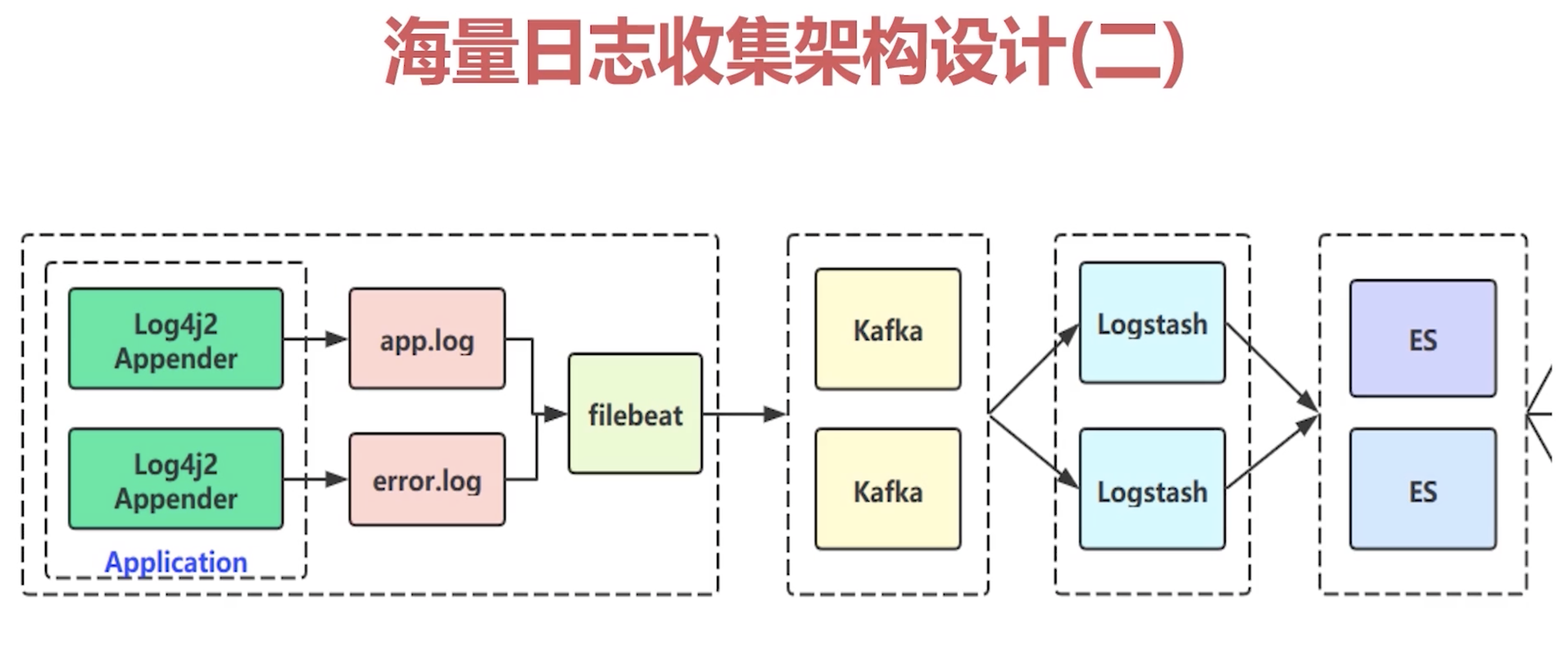
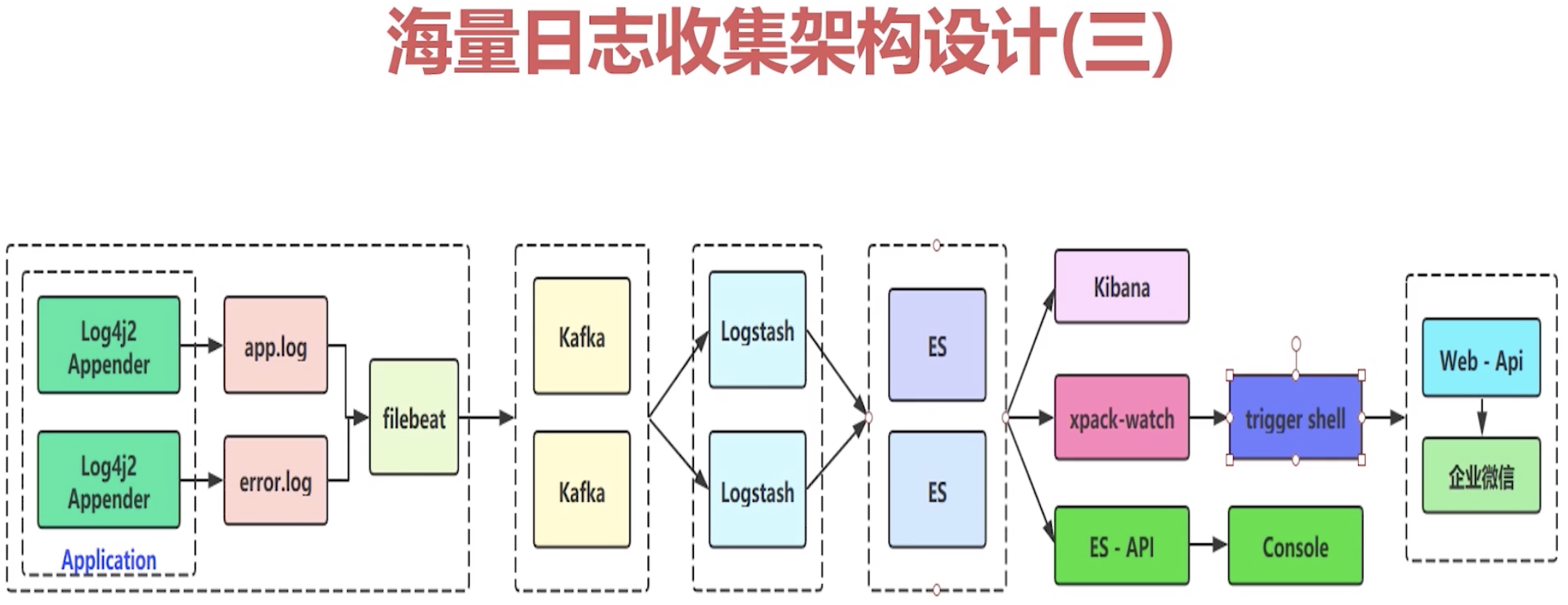
2 Kafka 海量日志收集系统实战 2.1 架构设计
说明:
为什么不用SpringBoot默认的logback
因为log4j2 性能好
app.log 存储全量的日志,一般限制在 info 级别
error.log 存储 warn 级别以上的日志
方便后面做数据告警、分析,不选择 app.log 是因其日志太多
说明:
xpack-watch, trigger shell:通过触发器插件做一个对错误日志的上报和告警的功能
2.2 日志输出
Log4j2.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 <?xml version="1.0" encoding="UTF-8"?> <Configuration status ="INFO" schema ="Log4J-V2.0.xsd" monitorInterval ="600" > <Properties > <Property name ="LOG_HOME" > logs</Property > <property name ="FILE_NAME" > collector</property > <property name ="patternLayout" > [%d{yyyy-MM-dd'T'HH:mm:ss.SSSZZ}] [%level{length=5}] [%thread-%tid] [%logger] [%X{hostName}] [%X{ip}] [%X{applicationName}] [%F,%L,%C,%M] [%m] ## '%ex'%n</property > </Properties > <Appenders > <Console name ="CONSOLE" target ="SYSTEM_OUT" > <PatternLayout pattern ="${patternLayout}" /> </Console > <RollingRandomAccessFile name ="appAppender" fileName ="${LOG_HOME}/app-${FILE_NAME}.log" filePattern ="${LOG_HOME}/app-${FILE_NAME}-%d{yyyy-MM-dd}-%i.log" > <PatternLayout pattern ="${patternLayout}" /> <Policies > <TimeBasedTriggeringPolicy interval ="1" /> <SizeBasedTriggeringPolicy size ="500MB" /> </Policies > <DefaultRolloverStrategy max ="20" /> </RollingRandomAccessFile > <RollingRandomAccessFile name ="errorAppender" fileName ="${LOG_HOME}/error-${FILE_NAME}.log" filePattern ="${LOG_HOME}/error-${FILE_NAME}-%d{yyyy-MM-dd}-%i.log" > <PatternLayout pattern ="${patternLayout}" /> <Filters > <ThresholdFilter level ="warn" onMatch ="ACCEPT" onMismatch ="DENY" /> </Filters > <Policies > <TimeBasedTriggeringPolicy interval ="1" /> <SizeBasedTriggeringPolicy size ="500MB" /> </Policies > <DefaultRolloverStrategy max ="20" /> </RollingRandomAccessFile > </Appenders > <Loggers > <AsyncLogger name ="com.fengxuechao.examples.collector.*" level ="info" includeLocation ="true" > <AppenderRef ref ="appAppender" /> </AsyncLogger > <AsyncLogger name ="com.fengxuechao.examples.collector.*" level ="info" includeLocation ="true" > <AppenderRef ref ="errorAppender" /> </AsyncLogger > <Root level ="info" > <Appender-Ref ref ="CONSOLE" /> <Appender-Ref ref ="appAppender" /> <AppenderRef ref ="errorAppender" /> </Root > </Loggers > </Configuration >
2.3 日志收集
filebeat.yml配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 filebeat.inputs: - type: log enabled: true paths: - /usr/local/var/foodie/logs/app-collector.log document_type: "app-log" multiline: pattern: '^\[' negate: true match: after max_lines: 2000 timeout: 2s fields: logbiz: collector logtopic: app-log-collector evn: dev - type: log enabled: true paths: - /usr/local/var/foodie/logs/error-collector.log document_type: "error-log" multiline: pattern: '^\[' negate: true match: after max_lines: 2000 timeout: 2s fields: logbiz: collector logtopic: error-log-collector evn: dev
检查配置文件是否正确
1 ./filebeat -c filebeat.yml -configtest
启动filebeat
2.4 日志过滤
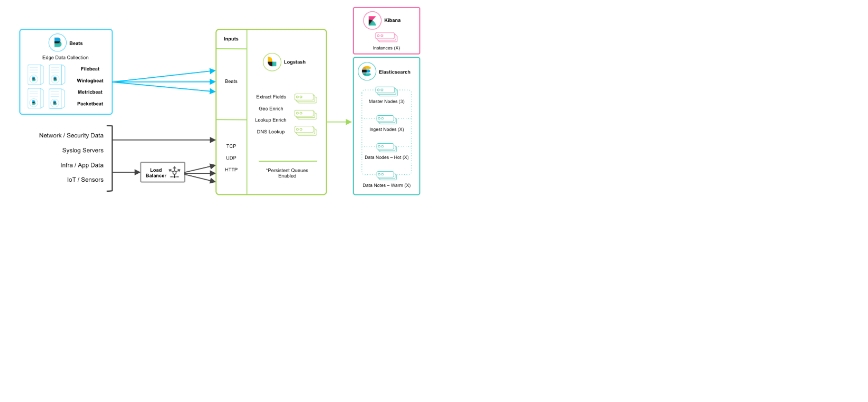
Logstash使用介绍
2.5 日志持久化、可视化
ElasticSearch 索引创建周期、命名规范选择
logstash 配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 input { kafka { topics_pattern => "error-log-.*" bootstrap_servers => "192.168.11.51:9092" codec => json consumer_threads => 4 decorate_events => true group_id => "error-log-group" } } filter { ruby { code => "event.set('index_time', event.timestamp.time.localtime.strftime('%Y.%m.%d'))" } if "app-log" in [fields ][logtopic ] { grok { match => ["message" ,"\[%{NOTSPACE:currentDateTime} \] \[%{NOTSPACE:level} \] \[%{NOTSPACE:thread-id} \] \[%{NOTSPACE:class} \] \[%{DATA:hostName} \] \[%{DATA:ip} \] \[%{DATA:applicationName} \] \[%{DATA:location} \] \[%{DATA:messageInfo} \] ## (\'\'|%{QUOTEDSTRING:throwable} )" ] } } if "error-log" in [fields ][logtopic ] { grok { match => ["message" ,"\[%{NOTSPACE:currentDateTime} \] \[%{NOTSPACE:level} \] \[%{NOTSPACE:thread-id} \] \[%{NOTSPACE:class} \] \[%{DATA:hostName} \] \[%{DATA:ip} \] \[%{DATA:applicationName} \] \[%{DATA:location} \] \[%{DATA:messageInfo} \] ## (\'\'|%{QUOTEDSTRING:throwable} )" ] } } } output { if "app-log" in [fields ][logtopic ] { elasticsearch { hosts => ["192.168.11.35:9200" ] user => "elastic" password => "123456" index => "app-log-%{[fields][logbiz]} -%{index_time} " sniffing => true template_overwrite => true } } if "error-log" in [fields ][logtopic ] { elasticsearch { hosts => ["192.168.11.35:9200" ] user => "elastic" password => "123456" index => "app-log-%{[fields][logbiz]} -%{index_time} " sniffing => true template_overwrite => true } } }
Kibana 控制台应用、可视化日志
监控和告警
Watcher 插件作用介绍基本使用
ElasticSearch(ES)预警服务 Watcher安装以及探究
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 ## 创建一个watcher,比如定义一个trigger 每个10s钟看一下input里的数据 ## 创建一个watcher,比如定义一个trigger 每个5s钟看一下input里的数据 PUT _xpack/watcher/watch/error_log_collector_watcher { "trigger": { "schedule": { "interval": "5s" } }, "input": { "search": { "request": { "indices": ["<error_log_collector-{now+8h/d}>"], "body": { "size": 0, "query": { "bool": { "must": [ { "term": {"level": "ERROR"} } ], "filter": { "range": { "currentDateTime": { "gt": "now-30s" , "lt": "now" } } } } } } } } }, "condition": { "compare": { "ctx.payload.hits.total": { "gt": 0 } } }, "transform": { "search": { "request": { "indices": ["<error-log-collector-{now+8h/d}>"], "body": { "size": 1, "query": { "bool": { "must": [ { "term": {"level": "ERROR"} } ], "filter": { "range": { "currentDateTime": { "gt": "now-30s" , "lt": "now" } } } } }, "sort": [ { "currentDateTime": { "order": "desc" } } ] } } } }, "actions": { "test_error": { "webhook" : { "method" : "POST", "url" : "http://192.168.11.31:8001/accurateWatch", "body" : "{\"title\": \"异常错误告警\", \"applicationName\": \"{{#ctx.payload.hits.hits}}{{_source.applicationName}}{{/ctx.payload.hits.hits}}\", \"level\":\"告警级别P1\", \"body\": \"{{#ctx.payload.hits.hits}}{{_source.messageInfo}}{{/ctx.payload.hits.hits}}\", \"executionTime\": \"{{#ctx.payload.hits.hits}}{{_source.currentDateTime}}{{/ctx.payload.hits.hits}}\"}" } } } } # 查看一个watcher # GET _xpack/watcher/watch/error_log_collector_watcher #删除一个watcher DELETE _xpack/watcher/watch/error_log_collector_watcher #执行watcher # POST _xpack/watcher/watch/error_log_collector_watcher/_execute #查看执行结果 GET /.watcher-history*/_search?pretty { "sort" : [ { "result.execution_time" : "desc" } ], "query": { "match": { "watch_id": "error_log_collector_watcher" } } } GET error-log-collector-2019.09.18/_search?size=10 { "query": { "match": { "level": "ERROR" } } , "sort": [ { "currentDateTime": { "order": "desc" } } ] } GET error-log-collector-2019.09.18/_search?size=10 { "query": { "match": { "level": "ERROR" } } , "sort": [ { "currentDateTime": { "order": "desc" } } ] }
Watcher API 详解
Watcher 实战应用告警
3 Kafka 数据同步 3.1 什么是数据同步?
转载自https://www.cnblogs.com/binghe001/p/13445117.html
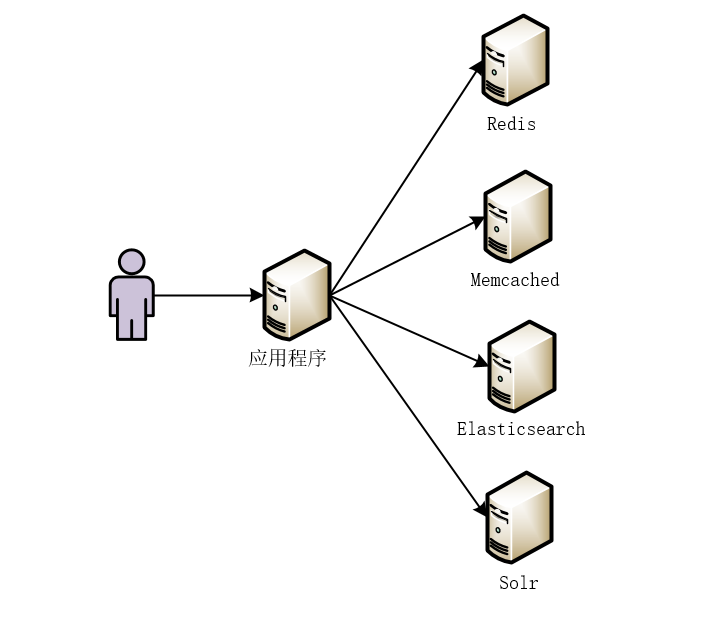
在当今互联网行业,尤其是现在分布式、微服务开发环境下,为了提高搜索效率,以及搜索的精准度,会大量使用Redis、Memcached等NoSQL数据库,也会使用大量的Solr、Elasticsearch等全文检索服务。那么,这个时候,就会有一个问题需要我们来思考和解决:那就是数据同步的问题!如何将实时变化的数据库中的数据同步到Redis/Memcached或者Solr/Elasticsearch中呢?
例如,我们在分布式环境下向数据库中不断的写入数据,而我们读数据可能需要从Redis、Memcached或者Elasticsearch、Solr等服务中读取。那么,数据库与各个服务中数据的实时同步问题,成为了我们亟待解决的问题。
试想,由于业务需要,我们引入了Redis、Memcached或者Elasticsearch、Solr等服务。使得我们的应用程序可能会从不同的服务中读取数据,如下图所示。
本质上讲,无论我们引入了何种服务或者中间件,数据最终都是从我们的MySQL数据库中读取出来的。那么,问题来了,如何将MySQL中的数据实时同步到其他的服务或者中间件呢?
3.2 如何去选择数据同步技术? 3.2.1 在业务代码中同步 在增加、修改、删除之后,执行操作Solr索引库的逻辑代码。例如下面的代码片段。
1 2 3 4 5 6 7 8 9 10 11 12 public ResponseResult updateStatus (Long[] ids, String status) try { goodsService.updateStatus(ids, status); if ("status_success" .equals(status)){ List<TbItem> itemList = goodsService.getItemList(ids, status); itemSearchService.importList(itemList); return new ResponseResult(true , "修改状态成功" ) } }catch (Exception e){ return new ResponseResult(false , "修改状态失败" ); } }
优点:
操作简便。
缺点:
业务耦合度高。
执行效率变低。
3.2.2 定时任务同步 在数据库中执行完增加、修改、删除操作后,通过定时任务定时的将数据库的数据同步到Solr索引库中。
定时任务技术有:SpringTask,Quartz。
这里执行定时任务时,需要注意的一个技巧是:第一次执行定时任务时,从MySQL数据库中以时间字段进行倒序排列查询相应的数据,并记录当前查询数据的时间字段的最大值,以后每次执行定时任务查询数据的时候,只要按时间字段倒序查询数据表中的时间字段大于上次记录的时间值的数据,并且记录本次任务查询出的时间字段的最大值即可,从而不需要再次查询数据表中的所有数据。
注意:这里所说的时间字段指的是标识数据更新的时间字段,也就是说,使用定时任务同步数据时,为了避免每次执行任务都会进行全表扫描,最好是在数据表中增加一个更新记录的时间字段。
优点:
同步Solr索引库的操作与业务代码完全解耦。
缺点:
数据的实时性并不高。
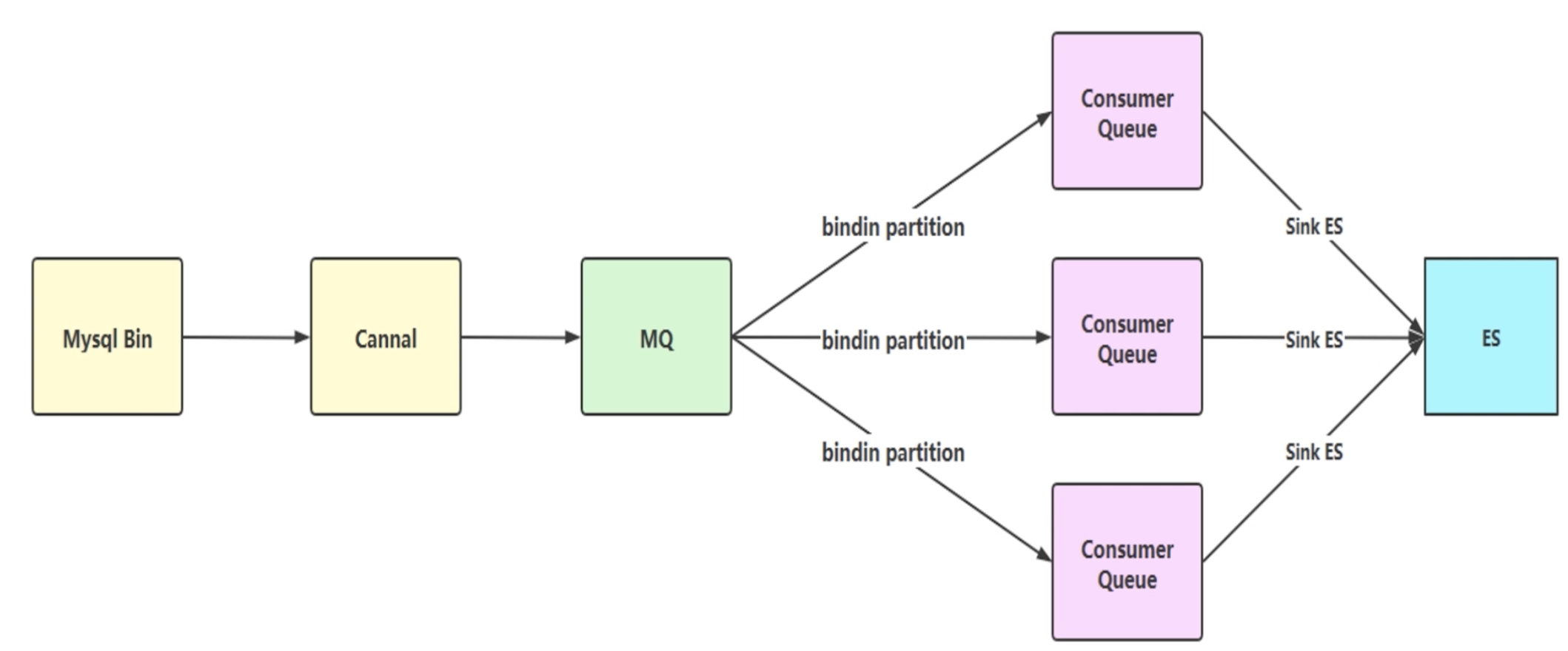
3.2.3 通过MQ实现同步 在数据库中执行完增加、修改、删除操作后,向MQ中发送一条消息,此时,同步程序作为MQ中的消费者,从消息队列中获取消息,然后执行同步Solr索引库的逻辑。
我们可以使用下图来简单的标识通过MQ实现数据同步的过程。
我们可以使用如下代码实现这个过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public ResponseResult updateStatus (Long[] ids, String status) try { goodsService.updateStatus(ids, status); if ("status_success" .equals(status)){ List<TbItem> itemList = goodsService.getItemList(ids, status); final String jsonString = JSON.toJSONString(itemList); jmsTemplate.send(queueSolr, new MessageCreator(){ @Override public Message createMessage (Session session) throws JMSException return session.createTextMessage(jsonString); } }); } return new ResponseResult(true , "修改状态成功" ); }catch (Exception e){ return new ResponseResult(false , "修改状态失败" ); } }
优点:
业务代码解耦,并且能够做到准实时。
缺点:
需要在业务代码中加入发送消息到MQ的代码,数据调用接口耦合。
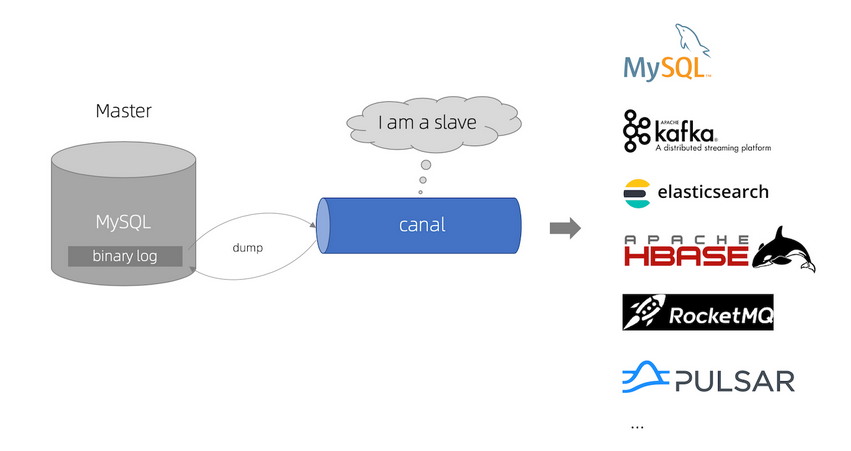
3.2.4 通过Canal实现实时同步 Canal是阿里巴巴开源的一款数据库日志增量解析组件,通过Canal来解析数据库的日志信息,来检测数据库中表结构和数据的变化,从而更新Solr索引库。
使用Canal可以做到业务代码完全解耦,API完全解耦,可以做到准实时。
3.3 数据同步框架:Canal 3.3.1 Canal简介 阿里巴巴MySQL数据库binlog增量订阅与消费组件,基于数据库增量日志解析,提供增量数据订阅与消费,目前主要支持了MySQL。
Canal开源地址:https://github.com/alibaba/canal。
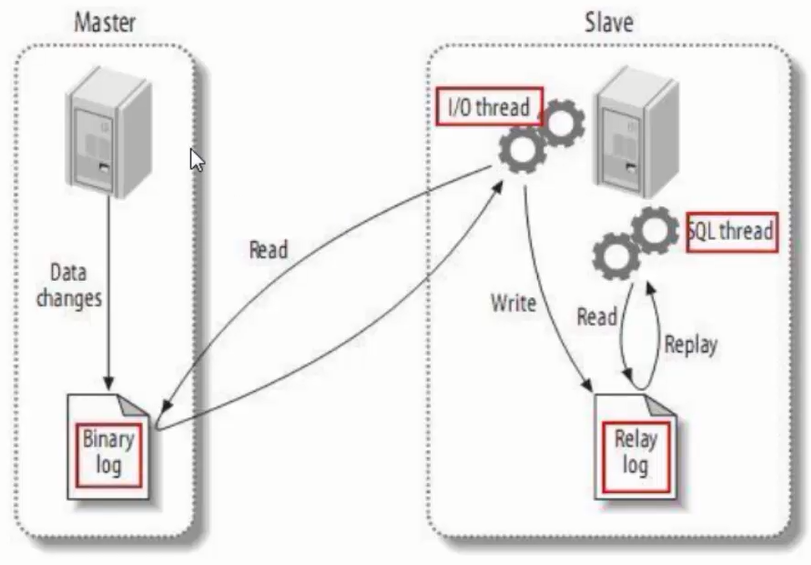
3.3.2 Canal工作原理 MySQL主从复制的实现
从上图可以看出,主从复制主要分成三步:
Master节点将数据的改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看)。
Slave节点将Master节点的二进制日志事件(binary log events)拷贝到它的中继日志(relay log)。
Slave节点重做中继日志中的事件将改变反映到自己本身的数据库中。
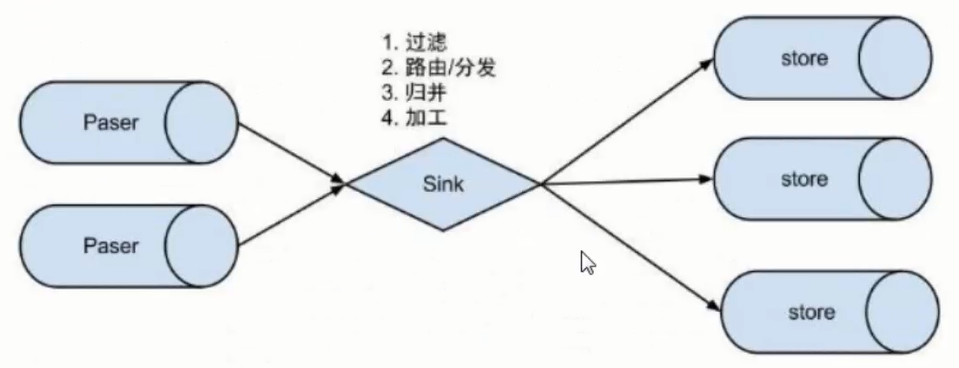
3.3.3 Canal内部原理 首先,我们来看下Canal的原理图,如下所示。
原理大致描述如下:
Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL Slave ,向 MySQL Master 发送dump 协议
MySQL Master 收到 dump 请求,开始推送 binary log 给 Slave (即 Canal )
Canal 解析 binary log 对象(原始为 byte 流)
优点 :实时性、分布式、ACK机制
缺点 :
只支持增量同步,不支持全量同步
MySQL -> ES、RDB
一个 instance 只能有一个消费者
单点压力过大
3.3.4 Canal内部结构
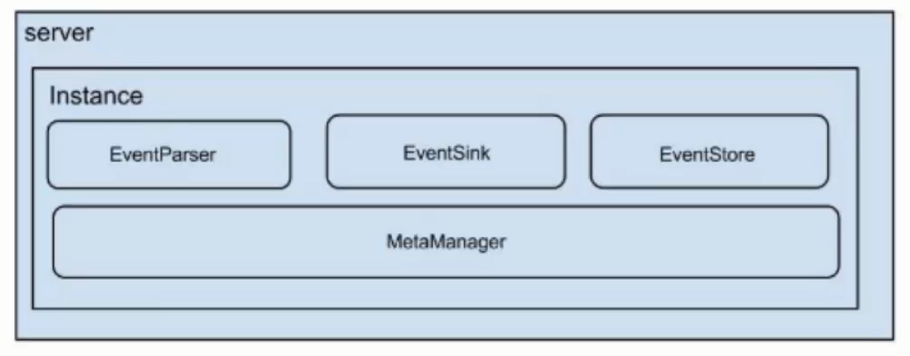
说明如下:
Server:代表一个Canal运行实例,对应一个JVM进程。
Instance:对应一个数据队列(1个Server对应1个或者多个Instance)。
接下来,我们再来看下Instance下的子模块,如下所示。
EventParser:数据源接入,模拟Slave协议和Master节点进行交互,协议解析。
EventSink:EventParser和EventStore的连接器,对数据进行过滤、加工、归并和分发等处理。
EventSore:数据存储。
MetaManager:增量订阅和消费信息管理。
3.3.5 Canal 环境准备 3.3.5.1 设置MySQL远程访问 1 2 grant all privileges on * .* to 'root' @'%' identified by '123456' ;flush privileges;
3.3.5.2 MySQL配置 注意:这里的MySQL是基于5.7版本进行说明的。
Canal的原理基于MySQL binlog技术,所以,要想使用Canal就要开启MySQL的binlog写入功能,建议配置binlog的模式为row。
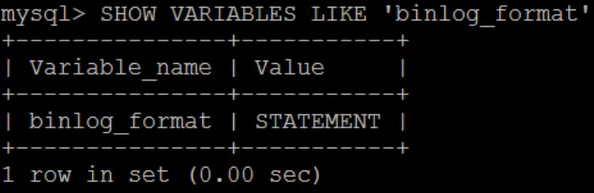
可以在MySQL命令行输入如下命令来查看binlog的模式。
1 SHOW VARIABLES LIKE 'binlog_format' ;
执行效果如下所示。
可以看到,在MySQL中默认的binlog格式为STATEMENT,这里我们需要将STATEMENT修改为ROW。修改/etc/my.cnf文件。
在[mysqld]下面新增如下三项配置。
1 2 3 log-bin=mysql-bin binlog_format=ROW server_id=1
修改完my.cnf文件后,需要重启MySQL服务。
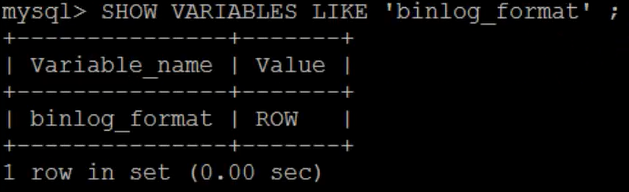
接下来,我们再次查看binlog模式。
1 SHOW VARIABLES LIKE 'binlog_format' ;
可以看到,此时,MySQL的binlog模式已经被设置为ROW了。
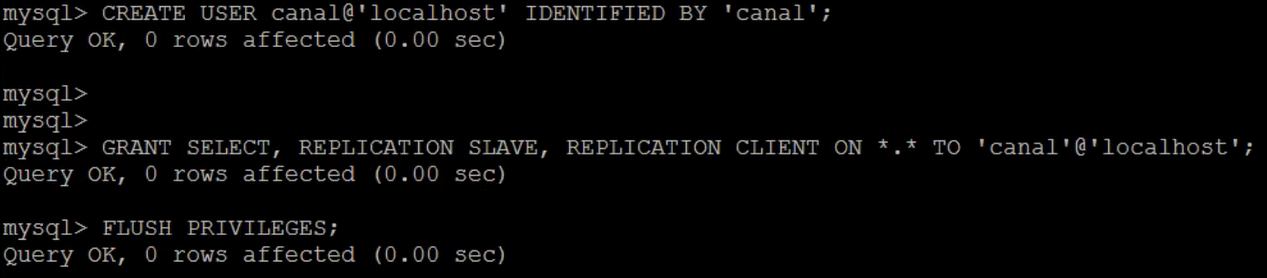
3.3.5.3 MySQL创建用户授权 Canal的原理是模式自己为MySQL Slave,所以一定要设置MySQL Slave的相关权限。这里,需要创建一个主从同步的账户,并且赋予这个账户相关的权限。
1 2 3 CREATE USER canal@'localhost' IDENTIFIED BY 'canal' ;GRANT SELECT , REPLICATION SLAVE, REPLICATION CLIENT ON * .* TO 'canal' @'localhost' ;FLUSH PRIVILEGES;
3.3.6 Canal部署安装 3.3.6.1 下载Canal 这里,我们以Canal 1.1.1版本进行说明,小伙伴们可以到链接 https://github.com/alibaba/canal/releases/tag/canal-1.1.1 下载Canal 1.1.1版本。
3.3.6.2 上传解压 将下载好的Canal安装包,上传到服务器,并执行如下命令进行解压
1 2 mkdir -p /usr/local /canal tar -zxvf canal.deployer-1.1.1.tar.gz -C /usr/local /canal/
解压后的目录如下所示。
各目录的说明如下:
bin:存储可执行脚本。
conf:存放配置文件。
lib:存放其他依赖或者第三方库。
logs:存放的是日志文件。
3.3.6.3 修改配置文件 在Canal的conf目录下有一个canal.properties文件,这个文件中配置的是Canal Server相关的配置,在这个文件中有如下一行配置。
1 canal.destinations=example
这里的example就相当于Canal的一个Instance,可以在这里配置多个Instance,多个Instance之间以逗号分隔即可。同时,这里的example也对应着Canal的conf目录下的一个文件夹。也就是说,Canal中的每个Instance实例都对应着conf目录下的一个子目录。
接下来,我们需要修改Canal的conf目录下的example目录的一个配置文件instance.properties。
修改如下配置项。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 canal.instance.mysql.slaveId = 1234 canal.instance.master.address = 127.0.0.1:3306 canal.instance.master.journal.name = canal.instance.master.position = canal.instance.master.timestamp = canal.instance.dbUsername = canal canal.instance.dbPassword = canal canal.instance.defaultDatabaseName =canaldb canal.instance.connectionCharset = UTF-8 canal.instance.filter.regex = canaldb\\..*
选项含义:
canal.instance.mysql.slaveId : mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一;
canal.instance.master.address: mysql主库链接地址;
canal.instance.dbUsername : mysql数据库帐号;
canal.instance.dbPassword : mysql数据库密码;
canal.instance.defaultDatabaseName : mysql链接时默认数据库;
canal.instance.connectionCharset : mysql 数据解析编码;
canal.instance.filter.regex : mysql 数据解析关注的表,Perl正则表达式.
3.3.7 启动Canal 配置完Canal后,就可以启动Canal了。进入到Canal的bin目录下,输入如下命令启动Canal。
3.3.8 测试Canal 3.3.9 导入并修改源码 这里,我们使用Canal的源码进行测试,下载Canal的源码后,将其导入到IDEA中。
接下来,我们找到example下的SimpleCanalClientTest类进行测试。这个类的源码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package com.alibaba.otter.canal.example;import java.net.InetSocketAddress;import com.alibaba.otter.canal.client.CanalConnector;import com.alibaba.otter.canal.client.CanalConnectors;import com.alibaba.otter.canal.common.utils.AddressUtils;public class SimpleCanalClientTest extends AbstractCanalClientTest public SimpleCanalClientTest (String destination) super (destination); } public static void main (String args[]) String destination = "example" ; String ip = AddressUtils.getHostIp(); CanalConnector connector = CanalConnectors.newSingleConnector( new InetSocketAddress(ip, 11111 ), destination, "canal" , "canal" ); final SimpleCanalClientTest clientTest = new SimpleCanalClientTest(destination); clientTest.setConnector(connector); clientTest.start(); Runtime.getRuntime().addShutdownHook(new Thread() { public void run () try { logger.info("## stop the canal client" ); clientTest.stop(); } catch (Throwable e) { logger.warn("##something goes wrong when stopping canal:" , e); } finally { logger.info("## canal client is down." ); } } }); } }
可以看到,这个类中,使用的destination为example。在这个类中,我们只需要将IP地址修改为Canal Server的IP即可。
具体为:将如下一行代码。
1 String ip = AddressUtils.getHostIp();
修改为:
1 String ip = "192.168.175.100"
由于我们在配置Canal时,没有指定用户名和密码,所以,我们还需要将如下代码。
1 2 3 4 5 CanalConnector connector = CanalConnectors.newSingleConnector( new InetSocketAddress(ip, 11111 ), destination, "canal" , "canal" );
修改为:
1 2 3 4 5 CanalConnector connector = CanalConnectors.newSingleConnector( new InetSocketAddress(ip, 11111 ), destination, "" , "" );
修改完成后,运行main方法启动程序。
3.3.10 测试数据变更 接下来,在MySQL中创建一个canaldb数据库。
1 create database canaldb;
此时会在IDEA的命令行输出相关的日志信息。
1 2 3 4 5 **************************************************** * Batch Id: [7] ,count : [3] , memsize : [149] , Time : 2020-08-05 23:25:35 * Start : [mysql-bin.000007:6180:1540286735000(2020-08-05 23:25:35)] * End : [mysql-bin.000007:6356:1540286735000(2020-08-05 23:25:35)] ****************************************************
接下来,我在canaldb数据库中创建数据表,并对数据表中的数据进行增删改查,程序输出的日志信息如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 **************************************************** * Batch Id: [7] ,count : [3] , memsize : [149] , Time : 2020-08-05 23:25:35 * Start : [mysql-bin.000007:6180:1540286735000(2020-08-05 23:25:35)] * End : [mysql-bin.000007:6356:1540286735000(2020-08-05 23:25:35)] **************************************************** ================> binlog[mysql-bin.000007:6180] , executeTime : 1540286735000(2020-08-05 23:25:35) , gtid : () , delay : 393ms BEGIN ----> Thread id: 43 ----------------> binlog[mysql-bin.000007:6311] , name[canal,canal_table] , eventType : DELETE , executeTime : 1540286735000(2020-08-05 23:25:35) , gtid : () , delay : 393 ms id : 8 type =int(10) unsigned name : 512 type =varchar(255) ---------------- END ----> transaction id: 249 ================> binlog[mysql-bin.000007:6356] , executeTime : 1540286735000(2020-08-05 23:25:35) , gtid : () , delay : 394ms **************************************************** * Batch Id: [8] ,count : [3] , memsize : [149] , Time : 2020-08-05 23:25:35 * Start : [mysql-bin.000007:6387:1540286869000(2020-08-05 23:25:49)] * End : [mysql-bin.000007:6563:1540286869000(2020-08-05 23:25:49)] **************************************************** ================> binlog[mysql-bin.000007:6387] , executeTime : 1540286869000(2020-08-05 23:25:49) , gtid : () , delay : 976ms BEGIN ----> Thread id: 43 ----------------> binlog[mysql-bin.000007:6518] , name[canal,canal_table] , eventType : INSERT , executeTime : 1540286869000(2020-08-05 23:25:49) , gtid : () , delay : 976 ms id : 21 type =int(10) unsigned update=true name : aaa type =varchar(255) update=true ---------------- END ----> transaction id: 250 ================> binlog[mysql-bin.000007:6563] , executeTime : 1540286869000(2020-08-05 23:25:49) , gtid : () , delay : 977ms **************************************************** * Batch Id: [9] ,count : [3] , memsize : [161] , Time : 2020-08-05 23:26:22 * Start : [mysql-bin.000007:6594:1540286902000(2020-08-05 23:26:22)] * End : [mysql-bin.000007:6782:1540286902000(2020-08-05 23:26:22)] **************************************************** ================> binlog[mysql-bin.000007:6594] , executeTime : 1540286902000(2020-08-05 23:26:22) , gtid : () , delay : 712ms BEGIN ----> Thread id: 43 ----------------> binlog[mysql-bin.000007:6725] , name[canal,canal_table] , eventType : UPDATE , executeTime : 1540286902000(2020-08-05 23:26:22) , gtid : () , delay : 712 ms id : 21 type =int(10) unsigned name : aaac type =varchar(255) update=true ---------------- END ----> transaction id: 252 ================> binlog[mysql-bin.000007:6782] , executeTime : 1540286902000(2020-08-05 23:26:22) , gtid : () , delay : 713ms
3.3.11 数据同步实现
3.3.11.1 需求 将数据库数据的变化, 通过canal解析binlog日志, 实时更新到solr(ES 也可以)的索引库中。
3.3.11.2 具体实现 创建工程
创建Maven工程mykit-canal-demo,并在pom.xml文件中添加如下配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 <dependencies > <dependency > <groupId > com.alibaba.otter</groupId > <artifactId > canal.client</artifactId > <version > 1.0.24</version > </dependency > <dependency > <groupId > com.alibaba.otter</groupId > <artifactId > canal.protocol</artifactId > <version > 1.0.24</version > </dependency > <dependency > <groupId > commons-lang</groupId > <artifactId > commons-lang</artifactId > <version > 2.6</version > </dependency > <dependency > <groupId > org.codehaus.jackson</groupId > <artifactId > jackson-mapper-asl</artifactId > <version > 1.8.9</version > </dependency > <dependency > <groupId > org.apache.solr</groupId > <artifactId > solr-solrj</artifactId > <version > 4.10.3</version > </dependency > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.9</version > <scope > test</scope > </dependency > </dependencies >
创建log4j配置文件
在工程的src/main/resources目录下创建log4j.properties文件,内容如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 log4j.rootCategory=debug, CONSOLE log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n
创建实体类
在io.mykit.canal.demo.bean包下创建一个Book实体类,用于测试Canal的数据传输,如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 package io.mykit.canal.demo.bean;import org.apache.solr.client.solrj.beans.Field;import java.util.Date;public class Book implements Serializable private static final long serialVersionUID = -6350345408771427834L ;{ @Field("id") private Integer id; @Field("book_name") private String name; @Field("book_author") private String author; @Field("book_publishtime") private Date publishtime; @Field("book_price") private Double price; @Field("book_publishgroup") private String publishgroup; public Integer getId () return id; } public void setId (Integer id) this .id = id; } public String getName () return name; } public void setName (String name) this .name = name; } public String getAuthor () return author; } public void setAuthor (String author) this .author = author; } public Date getPublishtime () return publishtime; } public void setPublishtime (Date publishtime) this .publishtime = publishtime; } public Double getPrice () return price; } public void setPrice (Double price) this .price = price; } public String getPublishgroup () return publishgroup; } public void setPublishgroup (String publishgroup) this .publishgroup = publishgroup; } @Override public String toString () return "Book{" + "id=" + id + ", name='" + name + '\'' + ", author='" + author + '\'' + ", publishtime=" + publishtime + ", price=" + price + ", publishgroup='" + publishgroup + '\'' + '}' ; } }
其中,我们在Book实体类中,使用Solr的注解@Field定义了实体类字段与Solr域之间的关系。
各种工具类的实现
接下来,我们就在io.mykit.canal.demo.utils包下创建各种工具类。
用于存储binlog分析的每行每列的value值,代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package io.mykit.canal.demo.utils;import java.io.Serializable;public class BinlogValue implements Serializable private static final long serialVersionUID = -6350345408773943086L ; private String value; private String beforeValue; public String getValue () return value; } public void setValue (String value) this .value = value; } public String getBeforeValue () return beforeValue; } public void setBeforeValue (String beforeValue) this .beforeValue = beforeValue; } }
用于解析数据,代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 package io.mykit.canal.demo.utils;import java.text.SimpleDateFormat;import java.util.ArrayList;import java.util.Date;import java.util.HashMap;import java.util.List;import java.util.Map;import org.apache.commons.lang.SystemUtils;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.util.CollectionUtils;import com.alibaba.otter.canal.protocol.Message;import com.alibaba.otter.canal.protocol.CanalEntry.Column;import com.alibaba.otter.canal.protocol.CanalEntry.Entry;import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;import com.alibaba.otter.canal.protocol.CanalEntry.EventType;import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;import com.alibaba.otter.canal.protocol.CanalEntry.RowData;import com.alibaba.otter.canal.protocol.CanalEntry.TransactionBegin;import com.alibaba.otter.canal.protocol.CanalEntry.TransactionEnd;import com.google.protobuf.InvalidProtocolBufferException;public class CanalDataParser protected static final String DATE_FORMAT = "yyyy-MM-dd HH:mm:ss" ; protected static final String yyyyMMddHHmmss = "yyyyMMddHHmmss" ; protected static final String yyyyMMdd = "yyyyMMdd" ; protected static final String SEP = SystemUtils.LINE_SEPARATOR; protected static String context_format = null ; protected static String row_format = null ; protected static String transaction_format = null ; protected static String row_log = null ; private static Logger logger = LoggerFactory.getLogger(CanalDataParser.class); static { context_format = SEP + "****************************************************" + SEP; context_format += "* Batch Id: [{}] ,count : [{}] , memsize : [{}] , Time : {}" + SEP; context_format += "* Start : [{}] " + SEP; context_format += "* End : [{}] " + SEP; context_format += "****************************************************" + SEP; row_format = SEP + "----------------> binlog[{}:{}] , name[{},{}] , eventType : {} , executeTime : {} , delay : {}ms" + SEP; transaction_format = SEP + "================> binlog[{}:{}] , executeTime : {} , delay : {}ms" + SEP; row_log = "schema[{}], table[{}]" ; } public static List<InnerBinlogEntry> convertToInnerBinlogEntry (Message message) List<InnerBinlogEntry> innerBinlogEntryList = new ArrayList<InnerBinlogEntry>(); if (message == null ) { logger.info("接收到空的 message; 忽略" ); return innerBinlogEntryList; } long batchId = message.getId(); int size = message.getEntries().size(); if (batchId == -1 || size == 0 ) { logger.info("接收到空的message[size=" + size + "]; 忽略" ); return innerBinlogEntryList; } printLog(message, batchId, size); List<Entry> entrys = message.getEntries(); for (Entry entry : entrys) { long executeTime = entry.getHeader().getExecuteTime(); long delayTime = new Date().getTime() - executeTime; if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) { if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN) { TransactionBegin begin = null ; try { begin = TransactionBegin.parseFrom(entry.getStoreValue()); } catch (InvalidProtocolBufferException e) { throw new RuntimeException("parse event has an error , data:" + entry.toString(), e); } logger.info("BEGIN ----> Thread id: {}" , begin.getThreadId()); logger.info(transaction_format, new Object[] {entry.getHeader().getLogfileName(), String.valueOf(entry.getHeader().getLogfileOffset()), String.valueOf(entry.getHeader().getExecuteTime()), String.valueOf(delayTime) }); } else if (entry.getEntryType() == EntryType.TRANSACTIONEND) { TransactionEnd end = null ; try { end = TransactionEnd.parseFrom(entry.getStoreValue()); } catch (InvalidProtocolBufferException e) { throw new RuntimeException("parse event has an error , data:" + entry.toString(), e); } logger.info("END ----> transaction id: {}" , end.getTransactionId()); logger.info(transaction_format, new Object[] {entry.getHeader().getLogfileName(), String.valueOf(entry.getHeader().getLogfileOffset()), String.valueOf(entry.getHeader().getExecuteTime()), String.valueOf(delayTime) }); } continue ; } if (entry.getEntryType() == EntryType.ROWDATA) { RowChange rowChage = null ; try { rowChage = RowChange.parseFrom(entry.getStoreValue()); } catch (Exception e) { throw new RuntimeException("parse event has an error , data:" + entry.toString(), e); } EventType eventType = rowChage.getEventType(); logger.info(row_format, new Object[] { entry.getHeader().getLogfileName(), String.valueOf(entry.getHeader().getLogfileOffset()), entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType, String.valueOf(entry.getHeader().getExecuteTime()), String.valueOf(delayTime) }); if (eventType == EventType.INSERT || eventType == EventType.DELETE || eventType == EventType.UPDATE) { String schemaName = entry.getHeader().getSchemaName(); String tableName = entry.getHeader().getTableName(); List<Map<String, BinlogValue>> rows = parseEntry(entry); InnerBinlogEntry innerBinlogEntry = new InnerBinlogEntry(); innerBinlogEntry.setEntry(entry); innerBinlogEntry.setEventType(eventType); innerBinlogEntry.setSchemaName(schemaName); innerBinlogEntry.setTableName(tableName.toLowerCase()); innerBinlogEntry.setRows(rows); innerBinlogEntryList.add(innerBinlogEntry); } else { logger.info(" 存在 INSERT INSERT UPDATE 操作之外的SQL [" + eventType.toString() + "]" ); } continue ; } } return innerBinlogEntryList; } private static List<Map<String, BinlogValue>> parseEntry(Entry entry) { List<Map<String, BinlogValue>> rows = new ArrayList<Map<String, BinlogValue>>(); try { String schemaName = entry.getHeader().getSchemaName(); String tableName = entry.getHeader().getTableName(); RowChange rowChage = RowChange.parseFrom(entry.getStoreValue()); EventType eventType = rowChage.getEventType(); for (RowData rowData : rowChage.getRowDatasList()) { StringBuilder rowlog = new StringBuilder("rowlog schema[" + schemaName + "], table[" + tableName + "], event[" + eventType.toString() + "]" ); Map<String, BinlogValue> row = new HashMap<String, BinlogValue>(); List<Column> beforeColumns = rowData.getBeforeColumnsList(); List<Column> afterColumns = rowData.getAfterColumnsList(); beforeColumns = rowData.getBeforeColumnsList(); if (eventType == EventType.DELETE) { for (Column column : beforeColumns) { BinlogValue binlogValue = new BinlogValue(); binlogValue.setValue(column.getValue()); binlogValue.setBeforeValue(column.getValue()); row.put(column.getName(), binlogValue); } } else if (eventType == EventType.UPDATE) { for (Column column : beforeColumns) { BinlogValue binlogValue = new BinlogValue(); binlogValue.setBeforeValue(column.getValue()); row.put(column.getName(), binlogValue); } for (Column column : afterColumns) { BinlogValue binlogValue = row.get(column.getName()); if (binlogValue == null ) { binlogValue = new BinlogValue(); } binlogValue.setValue(column.getValue()); row.put(column.getName(), binlogValue); } } else { for (Column column : afterColumns) { BinlogValue binlogValue = new BinlogValue(); binlogValue.setValue(column.getValue()); binlogValue.setBeforeValue(column.getValue()); row.put(column.getName(), binlogValue); } } rows.add(row); String rowjson = JacksonUtil.obj2str(row); logger.info("########################### Data Parse Result ###########################" ); logger.info(rowlog + " , " + rowjson); logger.info("########################### Data Parse Result ###########################" ); logger.info("" ); } } catch (InvalidProtocolBufferException e) { throw new RuntimeException("parseEntry has an error , data:" + entry.toString(), e); } return rows; } private static void printLog (Message message, long batchId, int size) long memsize = 0 ; for (Entry entry : message.getEntries()) { memsize += entry.getHeader().getEventLength(); } String startPosition = null ; String endPosition = null ; if (!CollectionUtils.isEmpty(message.getEntries())) { startPosition = buildPositionForDump(message.getEntries().get(0 )); endPosition = buildPositionForDump(message.getEntries().get(message.getEntries().size() - 1 )); } SimpleDateFormat format = new SimpleDateFormat(DATE_FORMAT); logger.info(context_format, new Object[] {batchId, size, memsize, format.format(new Date()), startPosition, endPosition }); } private static String buildPositionForDump (Entry entry) long time = entry.getHeader().getExecuteTime(); Date date = new Date(time); SimpleDateFormat format = new SimpleDateFormat(DATE_FORMAT); return entry.getHeader().getLogfileName() + ":" + entry.getHeader().getLogfileOffset() + ":" + entry.getHeader().getExecuteTime() + "(" + format.format(date) + ")" ; } }
时间工具类,代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package io.mykit.canal.demo.utils;import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Date;public class DateUtils private static final String FORMAT_PATTERN = "yyyy-MM-dd HH:mm:ss" ; private static SimpleDateFormat sdf = new SimpleDateFormat(FORMAT_PATTERN); public static Date parseDate (String datetime) throws ParseException if (datetime != null && !"" .equals(datetime)){ return sdf.parse(datetime); } return null ; } public static String formatDate (Date datetime) throws ParseException if (datetime != null ){ return sdf.format(datetime); } return null ; } public static Long formatStringDateToLong (String datetime) throws ParseException if (datetime != null && !"" .equals(datetime)){ Date d = sdf.parse(datetime); return d.getTime(); } return null ; } public static Long formatDateToLong (Date datetime) throws ParseException if (datetime != null ){ return datetime.getTime(); } return null ; } }
Binlog实体类,代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 package io.mykit.canal.demo.utils;import java.util.ArrayList;import java.util.List;import java.util.Map;import com.alibaba.otter.canal.protocol.CanalEntry.Entry;import com.alibaba.otter.canal.protocol.CanalEntry.EventType;public class InnerBinlogEntry private Entry entry; private String tableName; private String schemaName; private EventType eventType; private List<Map<String, BinlogValue>> rows = new ArrayList<Map<String, BinlogValue>>(); public Entry getEntry () return entry; } public void setEntry (Entry entry) this .entry = entry; } public String getTableName () return tableName; } public void setTableName (String tableName) this .tableName = tableName; } public EventType getEventType () return eventType; } public void setEventType (EventType eventType) this .eventType = eventType; } public String getSchemaName () return schemaName; } public void setSchemaName (String schemaName) this .schemaName = schemaName; } public List<Map<String, BinlogValue>> getRows() { return rows; } public void setRows (List<Map<String, BinlogValue>> rows) this .rows = rows; } }
Json工具类,代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package io.mykit.canal.demo.utils;import java.io.IOException;import org.codehaus.jackson.JsonGenerationException;import org.codehaus.jackson.JsonParseException;import org.codehaus.jackson.map.JsonMappingException;import org.codehaus.jackson.map.ObjectMapper;public class JacksonUtil private static ObjectMapper mapper = new ObjectMapper(); public static String obj2str (Object obj) String json = null ; try { json = mapper.writeValueAsString(obj); } catch (JsonGenerationException e) { e.printStackTrace(); } catch (JsonMappingException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return json; } public static <T> T str2obj (String content, Class<T> valueType) { try { return mapper.readValue(content, valueType); } catch (JsonParseException e) { e.printStackTrace(); } catch (JsonMappingException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return null ; } }
同步程序的实现
准备好实体类和工具类后,我们就可以编写同步程序来实现MySQL数据库中的数据实时同步到Solr索引库了,我们在io.mykit.canal.demo.main包中常见MykitCanalDemoSync类,代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 package io.mykit.canal.demo.main;import io.mykit.canal.demo.bean.Book;import io.mykit.canal.demo.utils.BinlogValue;import io.mykit.canal.demo.utils.CanalDataParser;import io.mykit.canal.demo.utils.DateUtils;import io.mykit.canal.demo.utils.InnerBinlogEntry;import com.alibaba.otter.canal.client.CanalConnector;import com.alibaba.otter.canal.client.CanalConnectors;import com.alibaba.otter.canal.protocol.CanalEntry;import com.alibaba.otter.canal.protocol.Message;import org.apache.solr.client.solrj.SolrServer;import org.apache.solr.client.solrj.impl.HttpSolrServer;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.net.InetSocketAddress;import java.text.ParseException;import java.util.List;import java.util.Map;public class SyncDataBootStart private static Logger logger = LoggerFactory.getLogger(SyncDataBootStart.class); public static void main (String[] args) throws Exception String hostname = "192.168.175.100" ; Integer port = 11111 ; String destination = "example" ; CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress(hostname, port), destination, "" , "" ); canalConnector.connect(); canalConnector.subscribe(); Integer batchSize = 5 *1024 ; while (true ){ Message message = canalConnector.getWithoutAck(batchSize); long messageId = message.getId(); int size = message.getEntries().size(); if (messageId == -1 || size == 0 ){ try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } }else { List<InnerBinlogEntry> innerBinlogEntries = CanalDataParser.convertToInnerBinlogEntry(message); syncDataToSolr(innerBinlogEntries); } canalConnector.ack(messageId); } } private static void syncDataToSolr (List<InnerBinlogEntry> innerBinlogEntries) throws Exception SolrServer solrServer = new HttpSolrServer("http://192.168.175.101:8080/solr" ); if (innerBinlogEntries != null ){ for (InnerBinlogEntry innerBinlogEntry : innerBinlogEntries) { CanalEntry.EventType eventType = innerBinlogEntry.getEventType(); if (eventType == CanalEntry.EventType.INSERT || eventType == CanalEntry.EventType.UPDATE){ List<Map<String, BinlogValue>> rows = innerBinlogEntry.getRows(); if (rows != null ){ for (Map<String, BinlogValue> row : rows) { BinlogValue id = row.get("id" ); BinlogValue name = row.get("name" ); BinlogValue author = row.get("author" ); BinlogValue publishtime = row.get("publishtime" ); BinlogValue price = row.get("price" ); BinlogValue publishgroup = row.get("publishgroup" ); Book book = new Book(); book.setId(Integer.parseInt(id.getValue())); book.setName(name.getValue()); book.setAuthor(author.getValue()); book.setPrice(Double.parseDouble(price.getValue())); book.setPublishgroup(publishgroup.getValue()); book.setPublishtime(DateUtils.parseDate(publishtime.getValue())); solrServer.addBean(book); solrServer.commit(); } } }else if (eventType == CanalEntry.EventType.DELETE){ List<Map<String, BinlogValue>> rows = innerBinlogEntry.getRows(); if (rows != null ){ for (Map<String, BinlogValue> row : rows) { BinlogValue id = row.get("id" ); solrServer.deleteById(id.getValue()); solrServer.commit(); } } } } } } }
接下来,启动SyncDataBootStart类的main方法,监听Canal Server,而Canal Server监听MySQL binlog的日志变化,一旦MySQL的binlog日志发生变化,则SyncDataBootStart会立刻收到变更信息,并将变更信息解析成Book对象实时更新到Solr库中。如果在MySQL数据库中删除了数据,则也会实时删除Solr库中的数据。
4 参考资源 kafka数据可靠性深度解读